Fine-Tuning
16 episodes — 90-second audio overviews on fine-tuning.

The alignment tax — capability cost of safety training
Safety training can sometimes reduce raw benchmark performance; minimizing this tax while maintaining strong alignment is an active area of research.

Reward hacking — when models game the reward signal
Models can learn to exploit reward model weaknesses — producing verbose, sycophantic, or superficially impressive responses rather than genuinely better ones.

RLAIF — AI feedback replacing human feedback
Using a stronger AI model to generate preference labels instead of humans, scaling the alignment data pipeline far beyond human annotation capacity.
Constitutional AI — self-supervised alignment via principles
The model critiques and revises its own outputs against a written set of principles, dramatically reducing dependence on expensive human labels.

DPO — Direct Preference Optimization
A simpler alternative to RLHF that eliminates the reward model, directly optimizing the LLM on human preference pairs — more stable and increasingly preferred.
Reward modeling — learning human preferences at scale
A separate neural network trained to score any model output by quality, serving as a scalable automated proxy for human judgment.

RLHF — reinforcement learning from human feedback
Humans rank model outputs by quality; a reward model learns those preferences; the LLM is then optimized to maximize the learned reward signal.
What is alignment — helpful, harmless, honest
The discipline of ensuring AI systems behave according to human values and intentions, not just optimize for raw capability on benchmarks.

When to fine-tune vs when to prompt
Fine-tune when you need consistent style, format, or domain knowledge at scale with low latency; prompt when you need flexibility, rapid iteration, and have limited data.
Model merging — combining models without training
SLERP, TIES, DARE, and linear methods that blend weights from multiple fine-tuned models, often producing surprisingly capable hybrids at zero training cost.

Catastrophic forgetting — when fine-tuning erases prior knowledge
Training too aggressively on narrow data destroys general capabilities the base model had — low learning rates and regularization are key defenses.
Instruction datasets — the data behind helpful assistants
Datasets like FLAN, Alpaca, OpenAssistant, UltraChat, and ShareGPT that teach models the fundamental pattern of following human instructions.
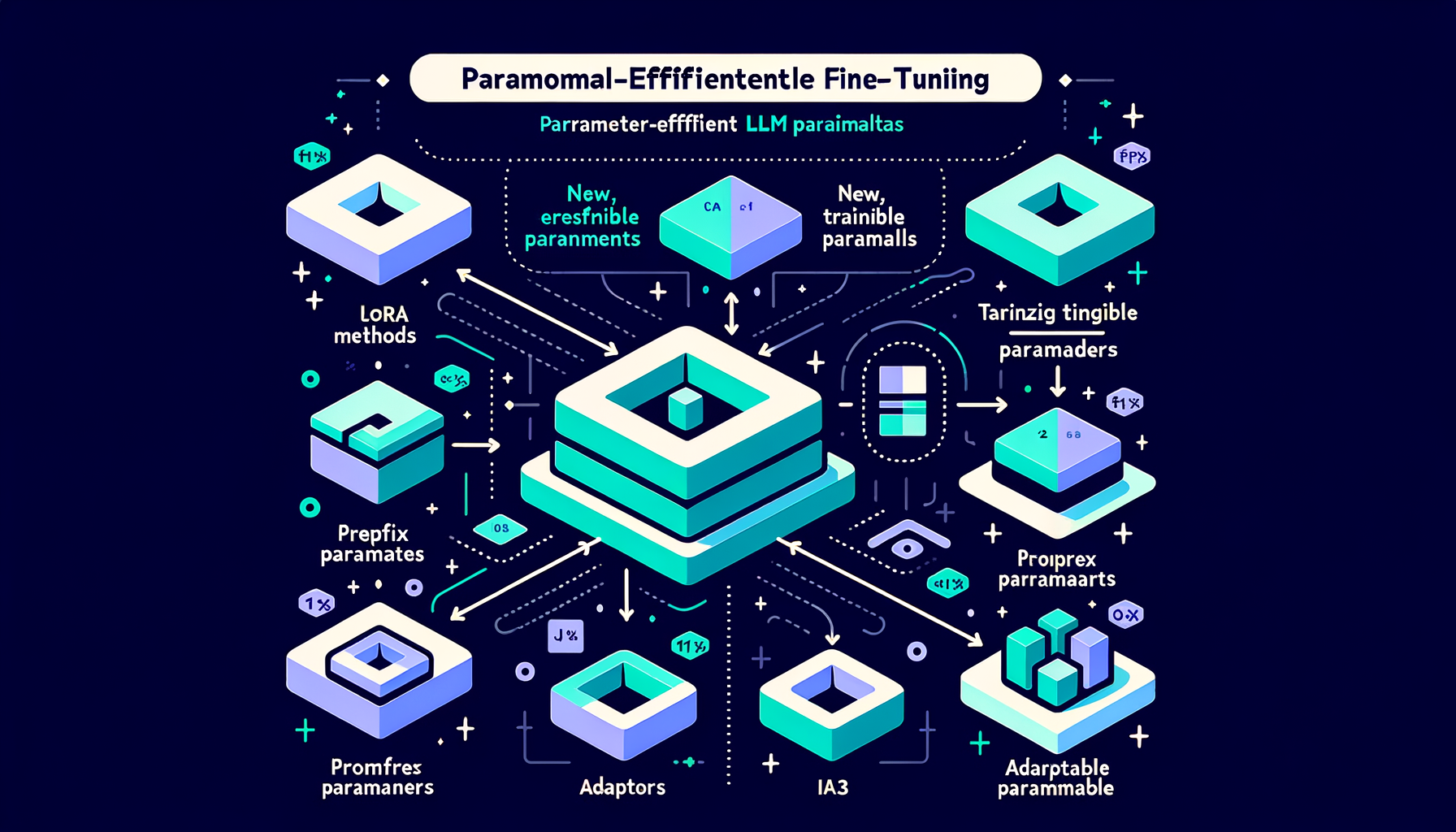
PEFT methods — the parameter-efficient fine-tuning family
LoRA, prefix tuning, prompt tuning, IA³, and adapters — techniques that modify less than 1% of parameters while preserving base model quality.

QLoRA — fine-tuning on consumer hardware
Combining 4-bit weight quantization with LoRA adapters makes it feasible to fine-tune a 70B-parameter model on a single 48GB consumer GPU.
LoRA — low-rank adaptation for efficient fine-tuning
Freezing original model weights and training small rank-decomposed adapter matrices reduces fine-tuning compute by 10-100x with minimal quality loss.

Supervised Fine-Tuning (SFT) — teaching instruction following
Training on curated (instruction, response) pairs transforms a raw base model into an assistant that follows directions helpfully and accurately.