All Topics

Distributed Training
5 episodes — 90-second audio overviews on distributed training.
1:39
DeepSpeed & FSDP — distributed training frameworks
Microsoft DeepSpeed (ZeRO stages 1-3) and PyTorch FSDP manage the complexity of sharding parameters, gradients, and optimizer states across clusters.
Distributed TrainingAI TrainingGenerative AIGenAI Explained2026-02-19
1:13
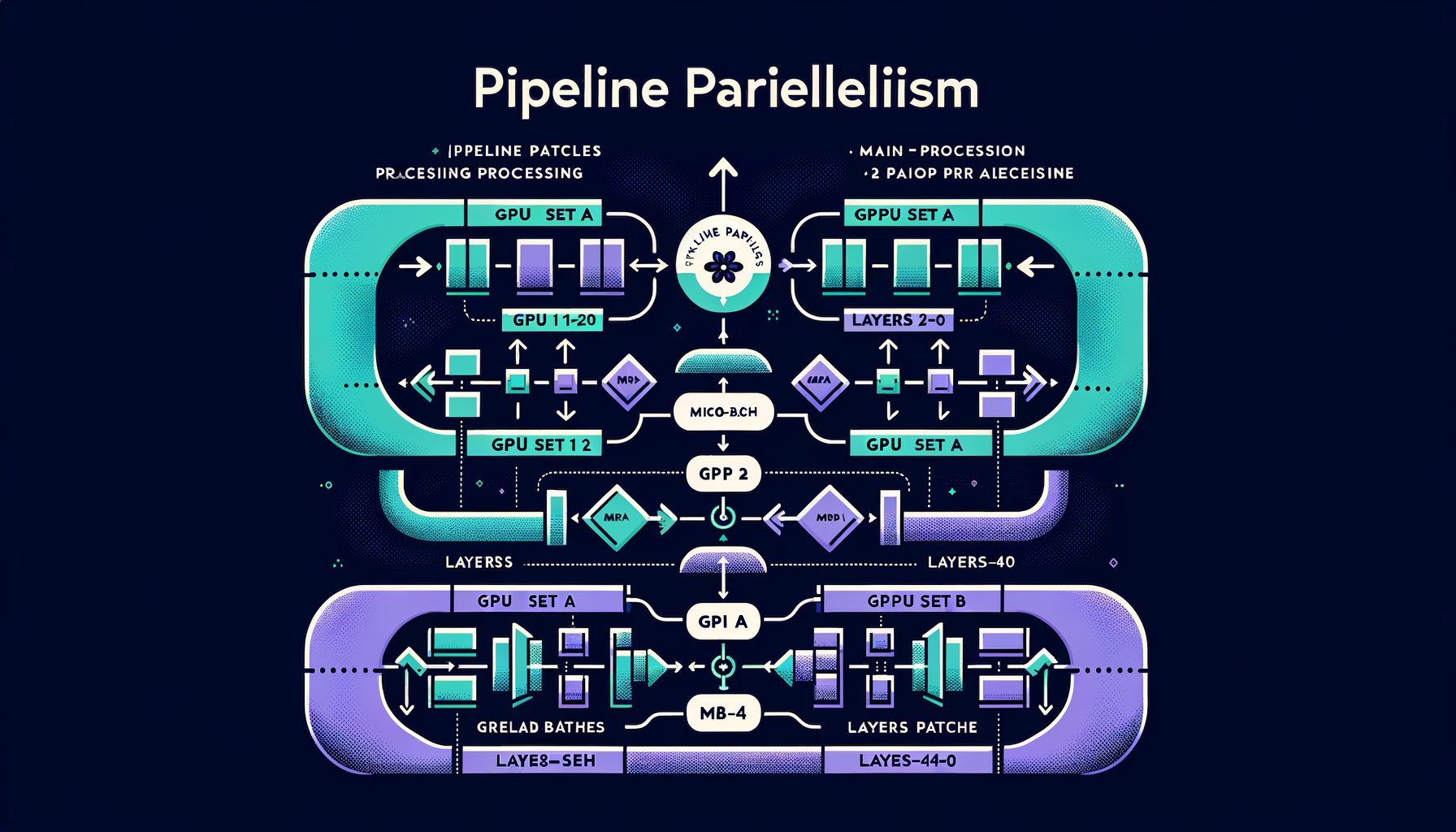
Pipeline parallelism — different layers on different GPUs
Layers 1-20 on GPU set A, layers 21-40 on GPU set B — combined with micro-batching to keep all devices busy.
Distributed TrainingAI TrainingGenerative AIGenAI Explained2026-02-19
1:28
Tensor parallelism — splitting individual layers across GPUs
Weight matrices are sharded across devices so each GPU computes a slice of every layer — required for models too large for one device's memory.
Distributed TrainingAI TrainingGenerative AIGenAI Explained2026-02-19
1:23
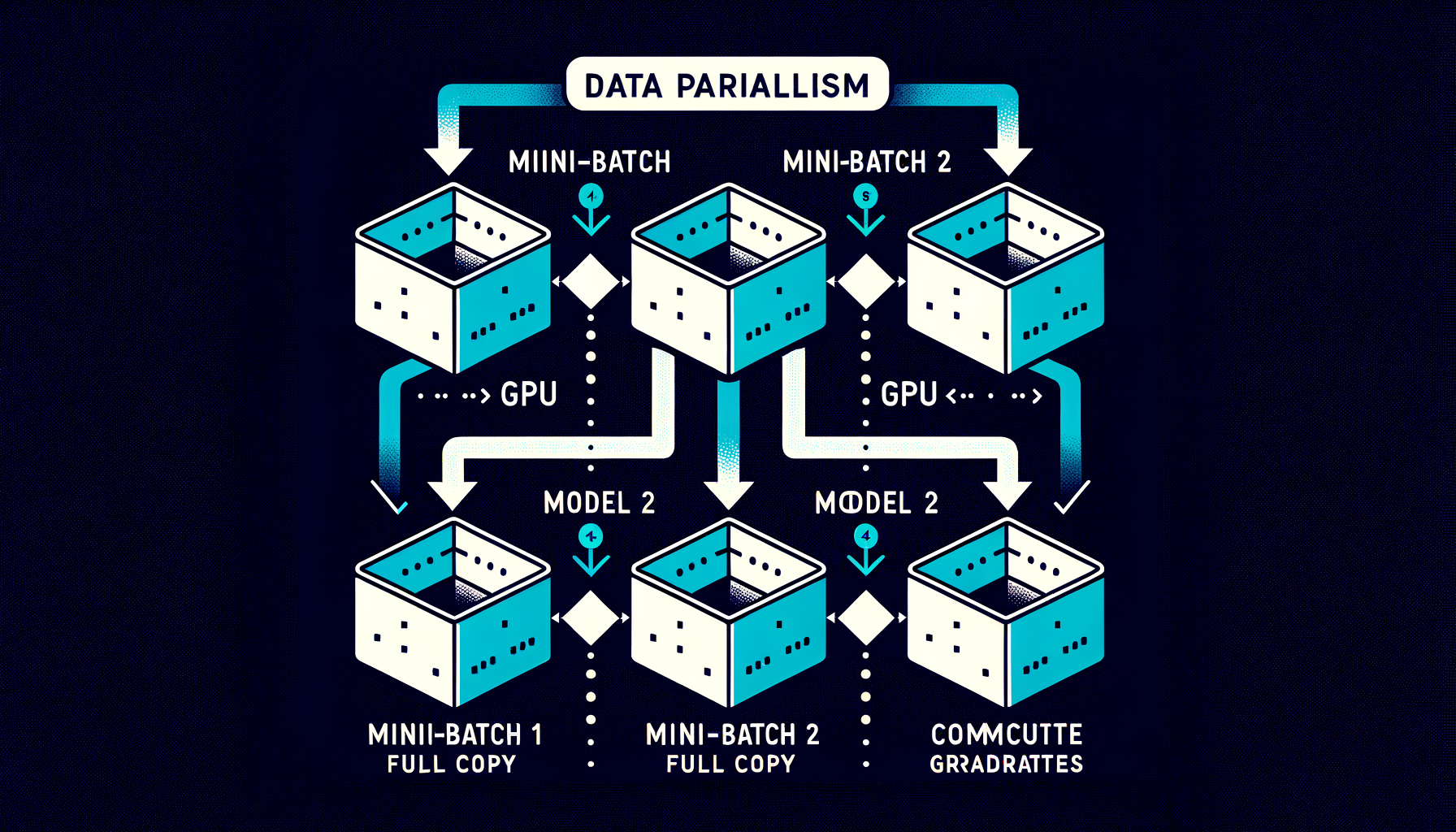
Data parallelism — same model, different data on each GPU
Every GPU holds a full copy of the model but processes different mini-batches; gradients are averaged across devices after each step.
Distributed TrainingAI TrainingGenerative AIGenAI Explained2026-02-19
1:52
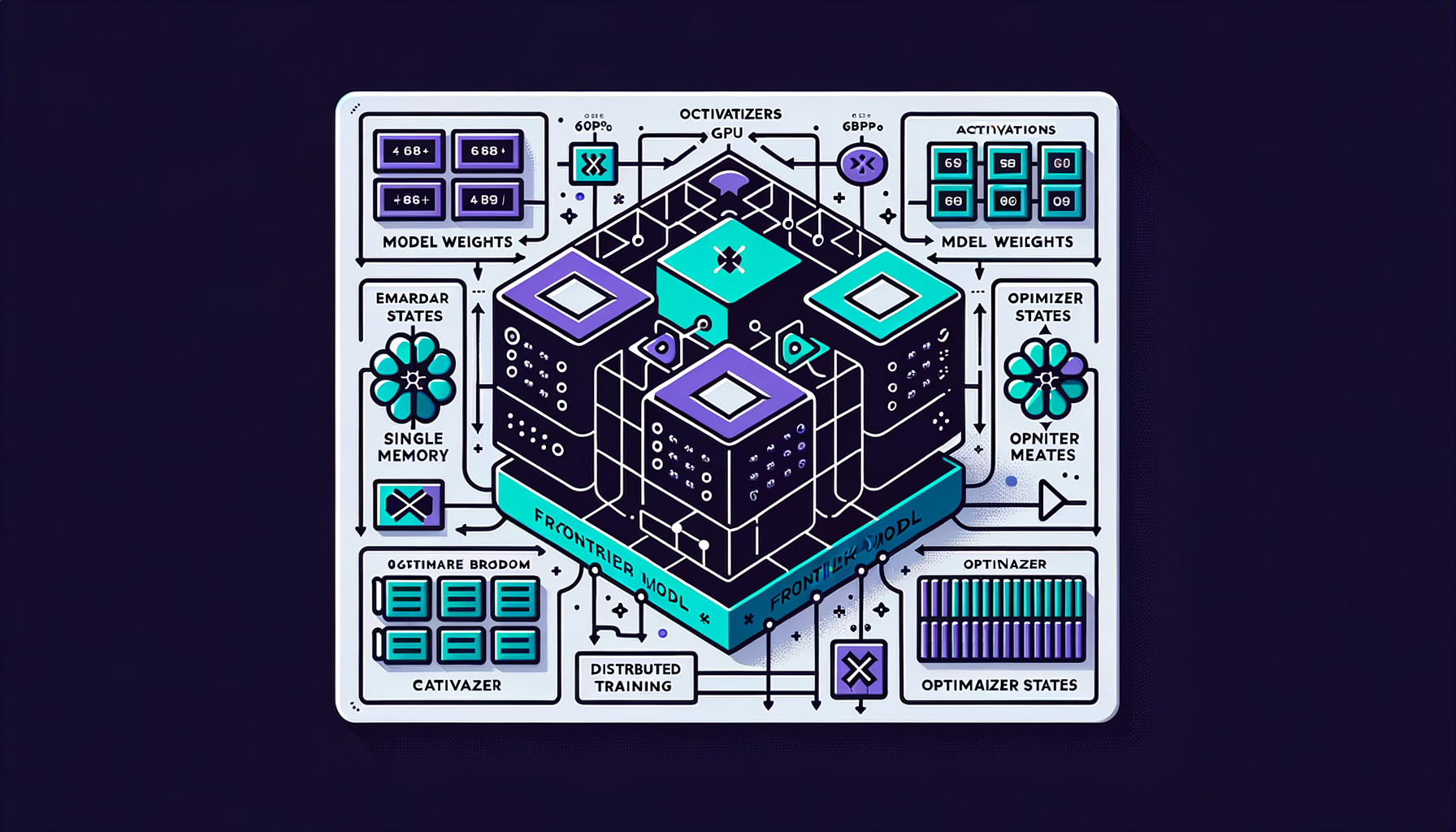
Why distributed training — no single GPU is enough
Frontier model weights, activations, and optimizer states vastly exceed any single GPU's memory; training requires coordinating thousands of devices.
Distributed TrainingAI TrainingGenerative AIGenAI Explained2026-02-19