Back to Bytes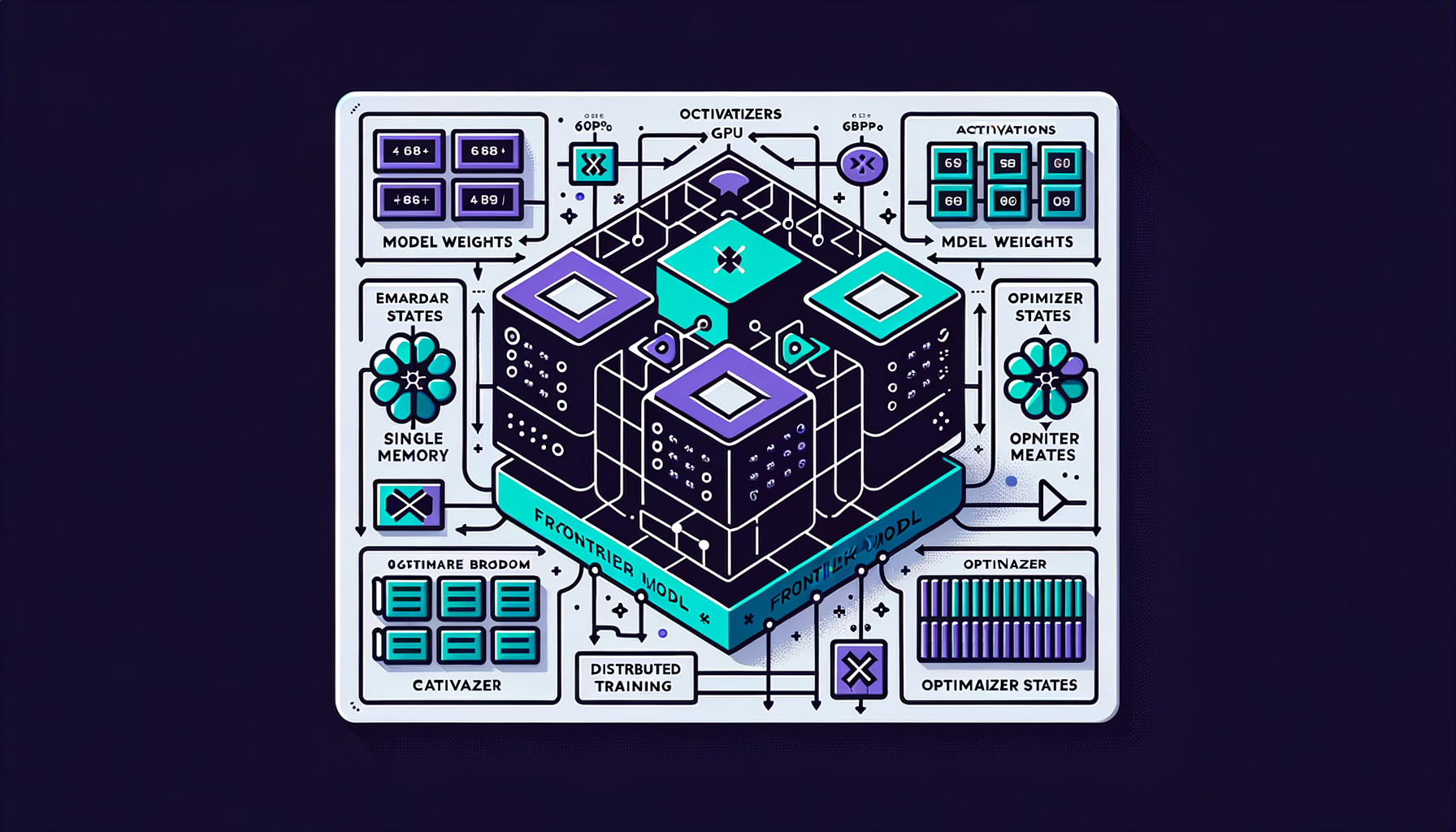
 GenBodha Bytes
GenBodha Bytes
Why distributed training — no single GPU is enough
Tap play · 90-second GenAI byte
0:00-1:52
Want to go deeper? Explore full courses with hands-on labs, quizzes, and chapter podcasts.
Tap play · 90-second GenAI byte
Want to go deeper? Explore full courses with hands-on labs, quizzes, and chapter podcasts.