AI Training
21 episodes — 90-second audio overviews on ai training.

When to fine-tune vs when to prompt
Fine-tune when you need consistent style, format, or domain knowledge at scale with low latency; prompt when you need flexibility, rapid iteration, and have limited data.
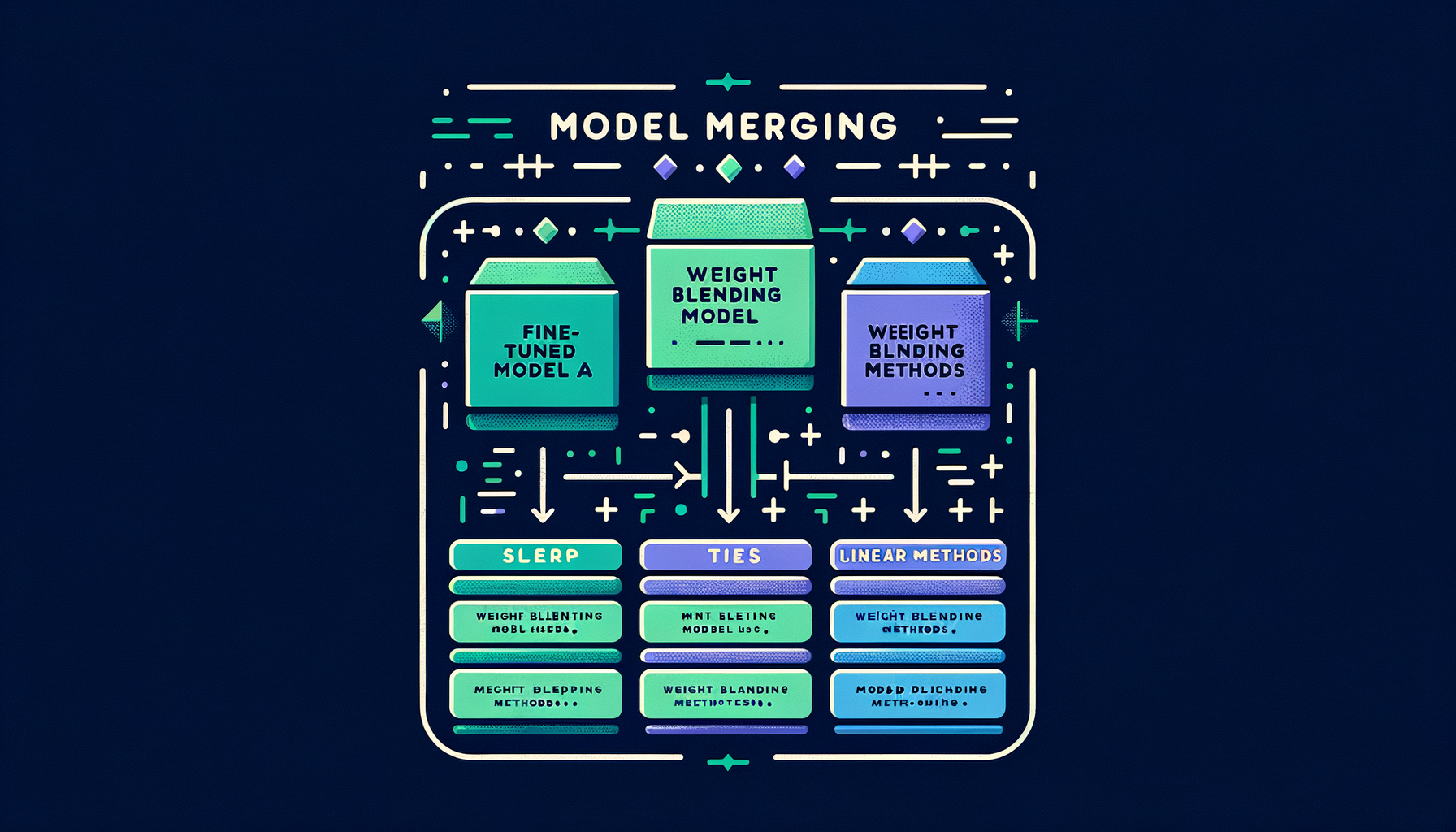
Model merging — combining models without training
SLERP, TIES, DARE, and linear methods that blend weights from multiple fine-tuned models, often producing surprisingly capable hybrids at zero training cost.

Catastrophic forgetting — when fine-tuning erases prior knowledge
Training too aggressively on narrow data destroys general capabilities the base model had — low learning rates and regularization are key defenses.
Instruction datasets — the data behind helpful assistants
Datasets like FLAN, Alpaca, OpenAssistant, UltraChat, and ShareGPT that teach models the fundamental pattern of following human instructions.
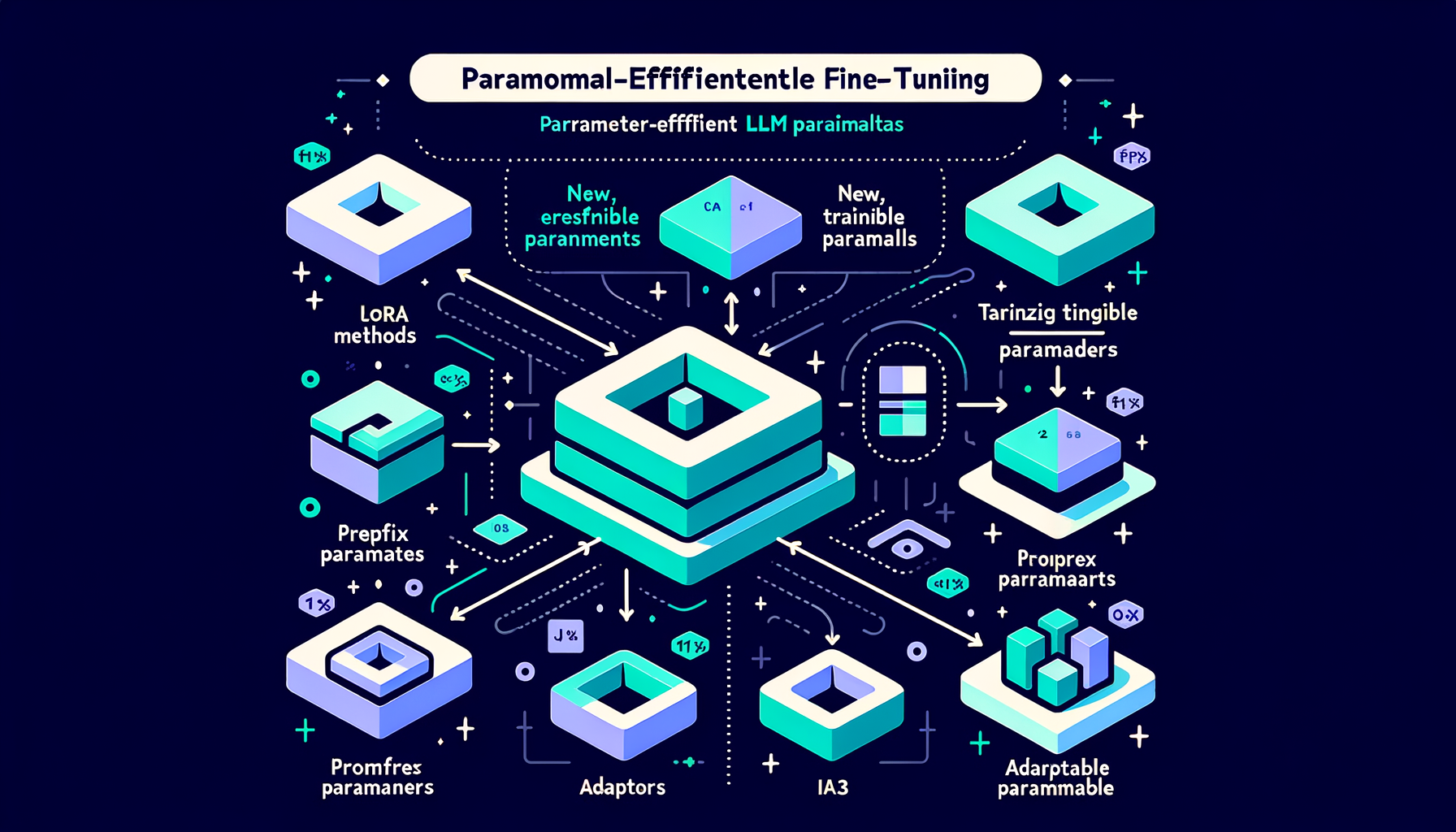
PEFT methods — the parameter-efficient fine-tuning family
LoRA, prefix tuning, prompt tuning, IA³, and adapters — techniques that modify less than 1% of parameters while preserving base model quality.

QLoRA — fine-tuning on consumer hardware
Combining 4-bit weight quantization with LoRA adapters makes it feasible to fine-tune a 70B-parameter model on a single 48GB consumer GPU.
LoRA — low-rank adaptation for efficient fine-tuning
Freezing original model weights and training small rank-decomposed adapter matrices reduces fine-tuning compute by 10-100x with minimal quality loss.

Supervised Fine-Tuning (SFT) — teaching instruction following
Training on curated (instruction, response) pairs transforms a raw base model into an assistant that follows directions helpfully and accurately.

DeepSpeed & FSDP — distributed training frameworks
Microsoft DeepSpeed (ZeRO stages 1-3) and PyTorch FSDP manage the complexity of sharding parameters, gradients, and optimizer states across clusters.
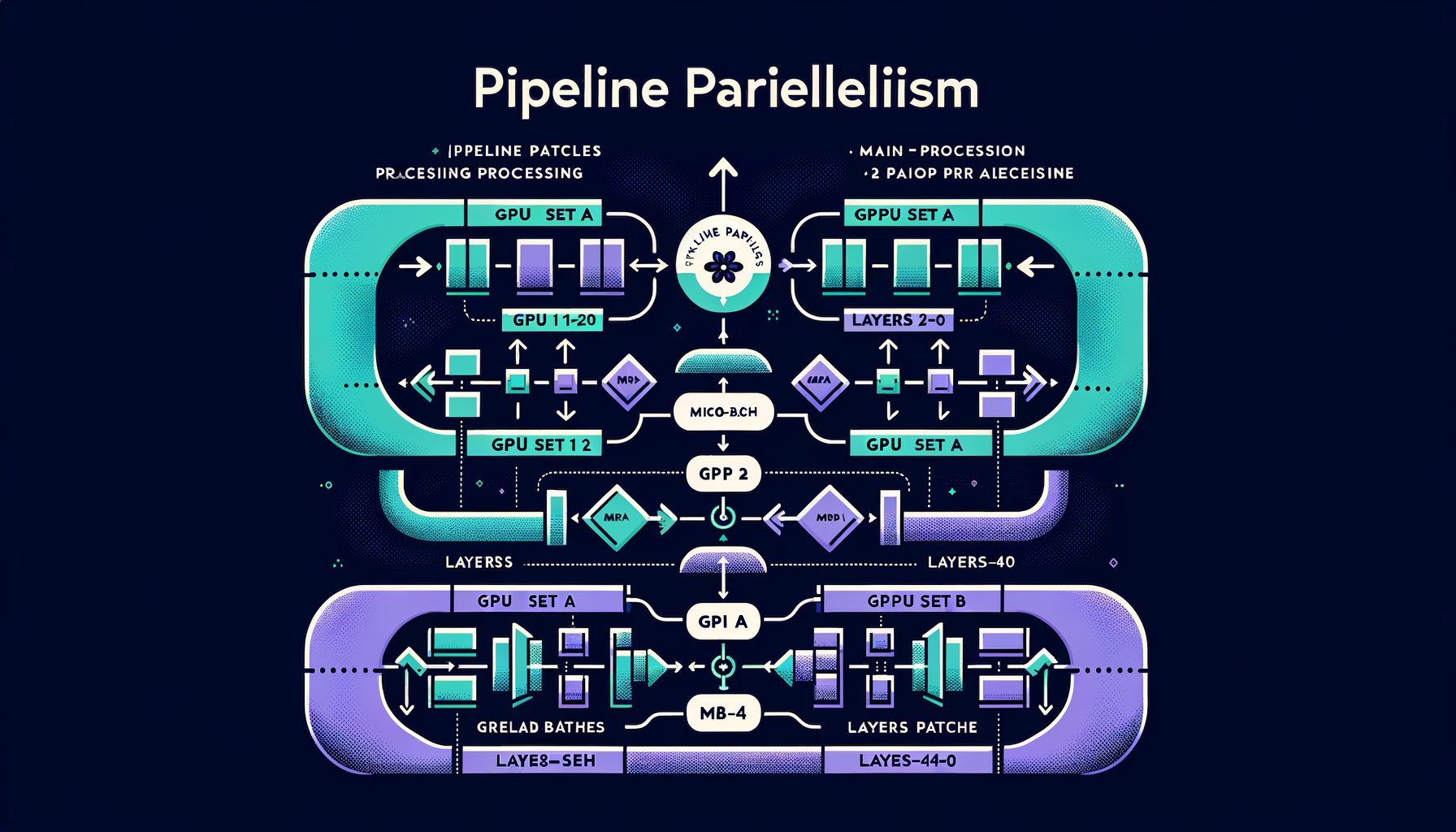
Pipeline parallelism — different layers on different GPUs
Layers 1-20 on GPU set A, layers 21-40 on GPU set B — combined with micro-batching to keep all devices busy.

Tensor parallelism — splitting individual layers across GPUs
Weight matrices are sharded across devices so each GPU computes a slice of every layer — required for models too large for one device's memory.
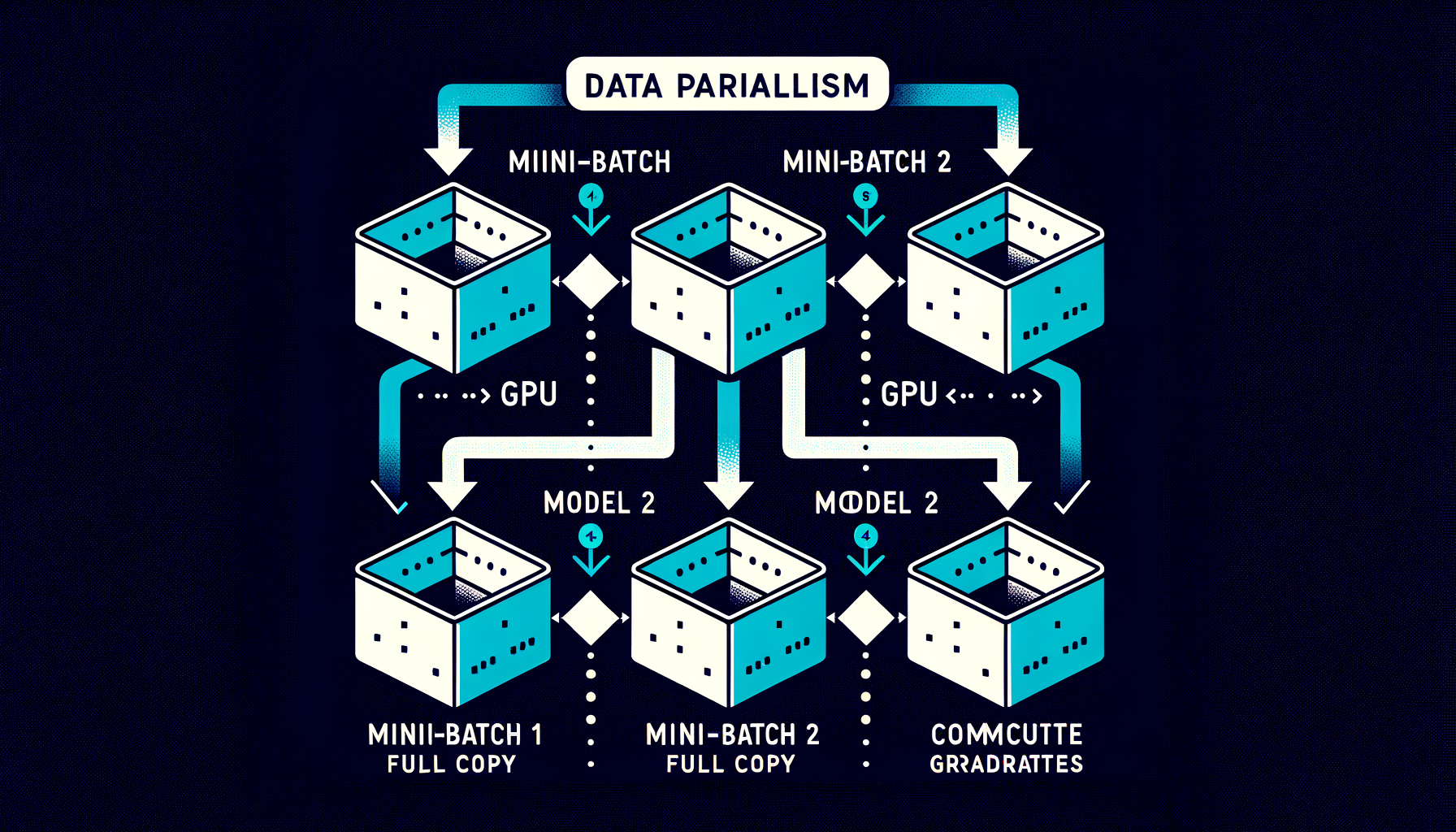
Data parallelism — same model, different data on each GPU
Every GPU holds a full copy of the model but processes different mini-batches; gradients are averaged across devices after each step.
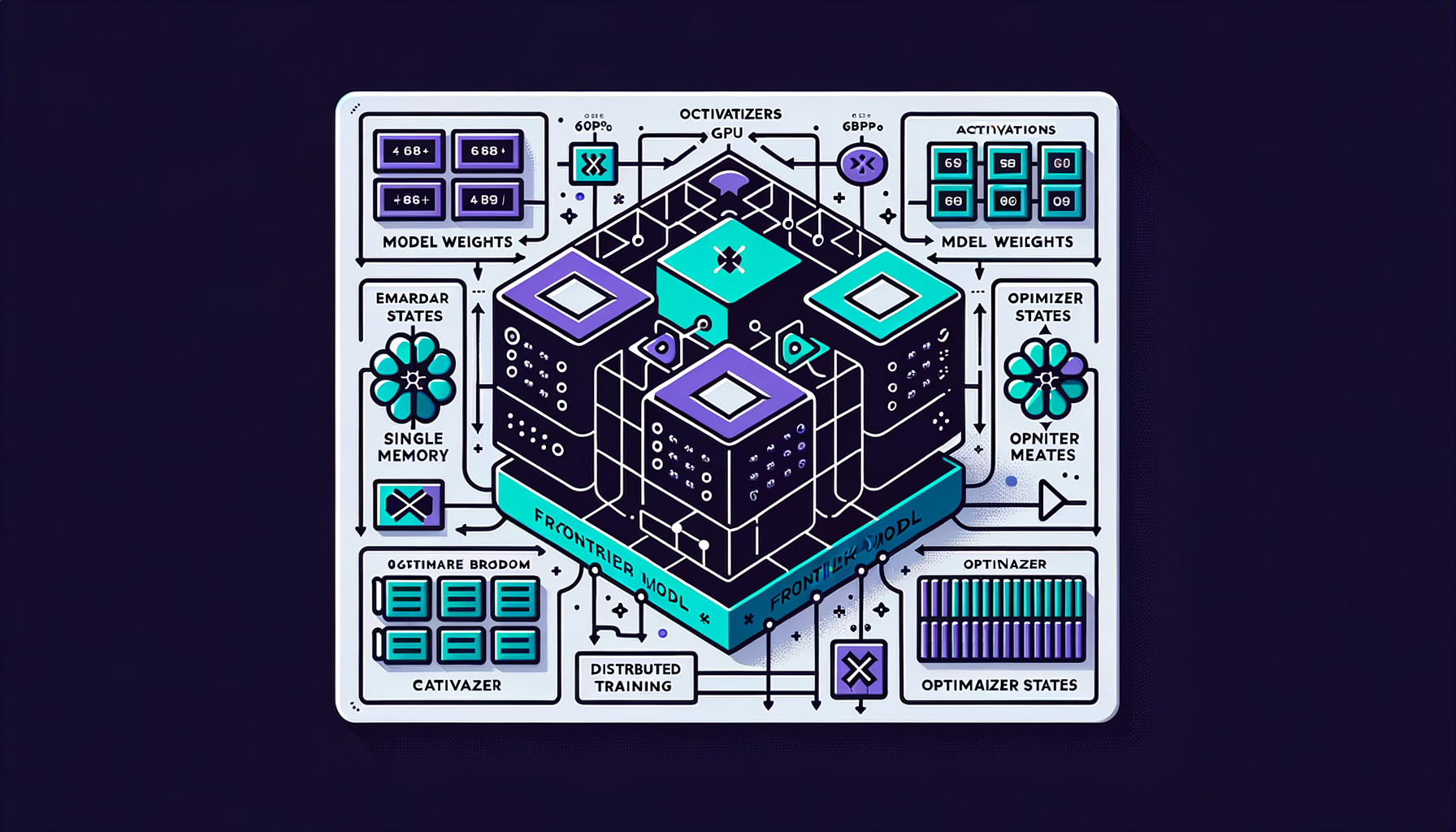
Why distributed training — no single GPU is enough
Frontier model weights, activations, and optimizer states vastly exceed any single GPU's memory; training requires coordinating thousands of devices.

Training compute — measuring cost in FLOPs and GPU-hours
Frontier models cost $50-100M+ to train; understanding compute budgets frames what is feasible at different organizational scales.
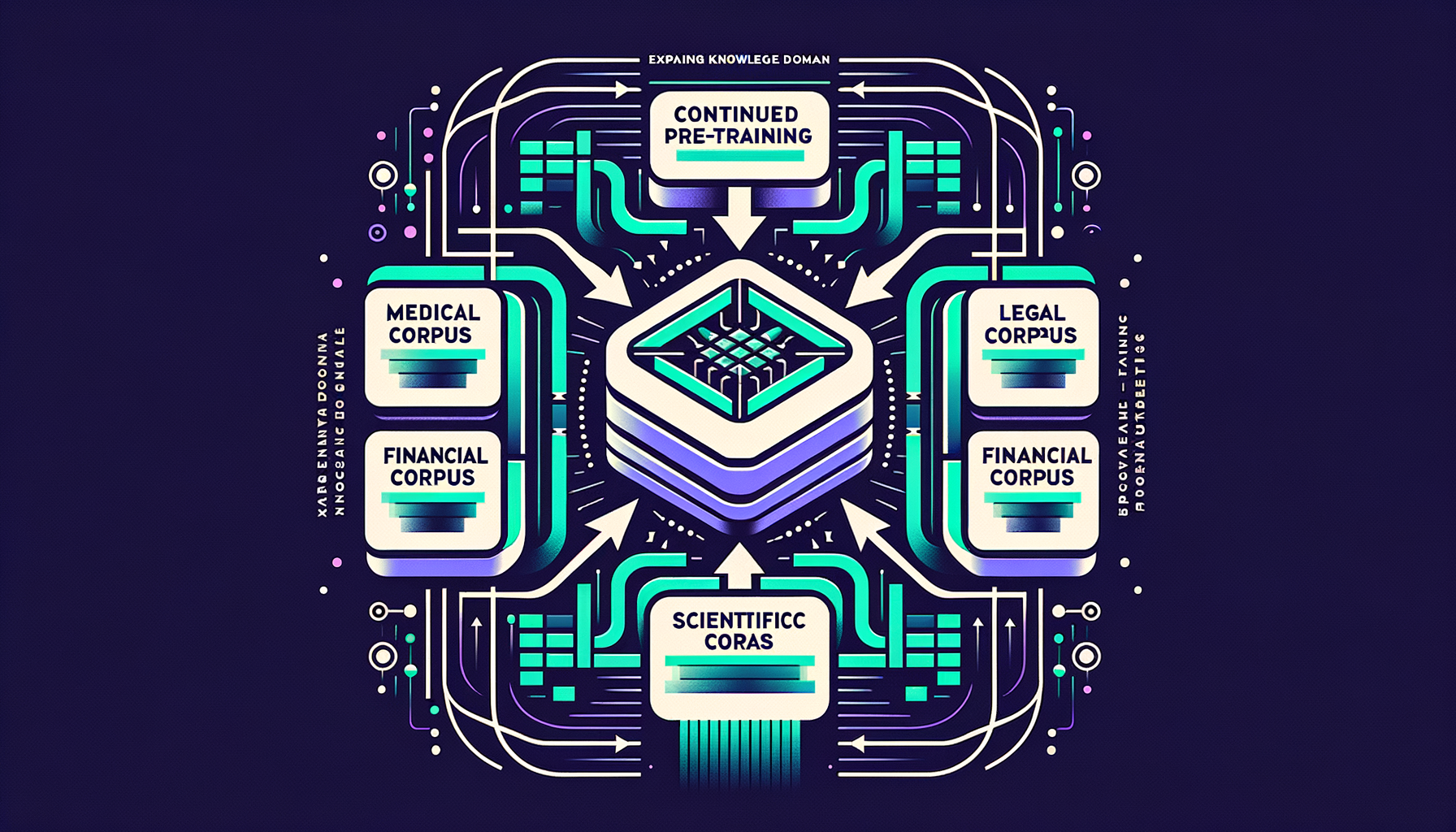
Continued pre-training — expanding a model's knowledge domain
Adding large domain-specific corpora (medical, legal, financial, scientific) to a base model to deepen expertise before fine-tuning.

Learning rate schedules — warming up and cooling down
Cosine decay with linear warmup is standard: gradually increase the learning rate at the start, then smoothly decrease it over the run.

Training loss curves — reading the heartbeat of pre-training
Smoothly decreasing loss means healthy training; spikes signal bad data batches, learning rate issues, or hardware failures.
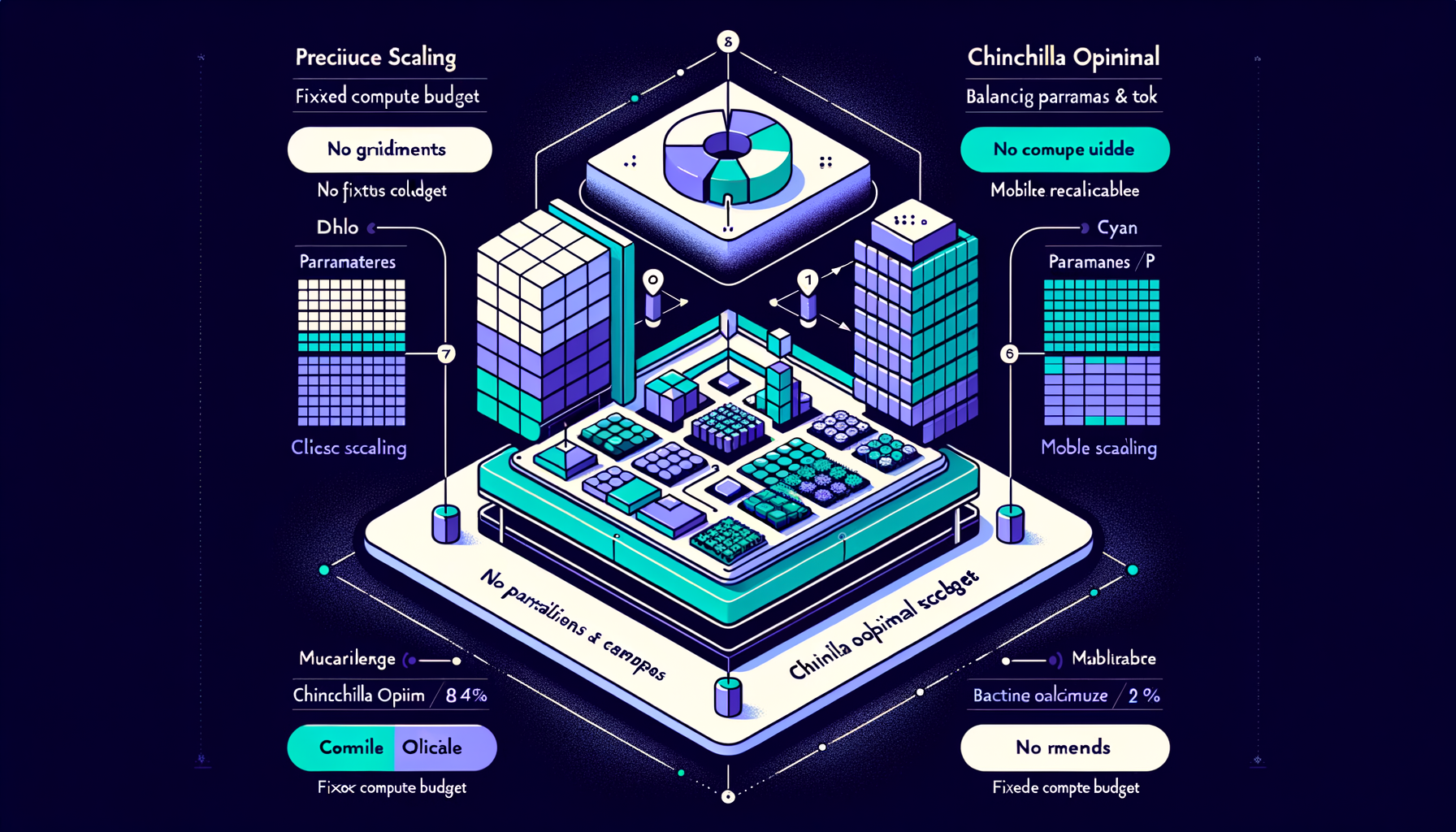
Chinchilla optimal — balancing parameters and tokens
DeepMind's research showing that for a fixed compute budget, the optimal strategy scales data and parameters in roughly equal proportion.
Data mixture & weighting — balancing domains during training
The ratio of code, math, science, conversation, and books in training data directly shapes which capabilities the finished model develops.
Training data curation — filtering the internet for quality
Deduplication, toxicity filtering, domain balancing, quality scoring, and PII removal transform raw web crawls into effective training corpora.
The pre-training recipe — data, compute, and objectives
Curating trillions of tokens, allocating thousands of GPUs, and running next-token prediction for weeks to months at enormous cost.