AI Alignment
13 episodes — 90-second audio overviews on ai alignment.
Overrefusal — when safety makes models too cautious
Excessive safety training causes refusal of clearly benign requests; calibrating the refusal boundary without compromising safety is a key alignment challenge.
Hallucination mitigation — grounding, retrieval, verification
RAG, self-consistency checks, citation requirements, confidence calibration, and retrieval verification reduce but never fully eliminate hallucination.
Why hallucinations happen — probability meets knowledge gaps
Models assign probability to all possible tokens including wrong ones; gaps in training data and distributional shift make some fabrication inevitable.

Types of hallucination — intrinsic vs extrinsic
Intrinsic hallucinations contradict the provided input; extrinsic hallucinations add unsupported claims from parametric memory — both undermine user trust.

Hallucination — when GenAI confidently fabricates information
Models generate plausible but factually wrong content because they optimize for fluency and pattern completion, not truth or accuracy.

The alignment tax — capability cost of safety training
Safety training can sometimes reduce raw benchmark performance; minimizing this tax while maintaining strong alignment is an active area of research.

Reward hacking — when models game the reward signal
Models can learn to exploit reward model weaknesses — producing verbose, sycophantic, or superficially impressive responses rather than genuinely better ones.

RLAIF — AI feedback replacing human feedback
Using a stronger AI model to generate preference labels instead of humans, scaling the alignment data pipeline far beyond human annotation capacity.
Constitutional AI — self-supervised alignment via principles
The model critiques and revises its own outputs against a written set of principles, dramatically reducing dependence on expensive human labels.

DPO — Direct Preference Optimization
A simpler alternative to RLHF that eliminates the reward model, directly optimizing the LLM on human preference pairs — more stable and increasingly preferred.
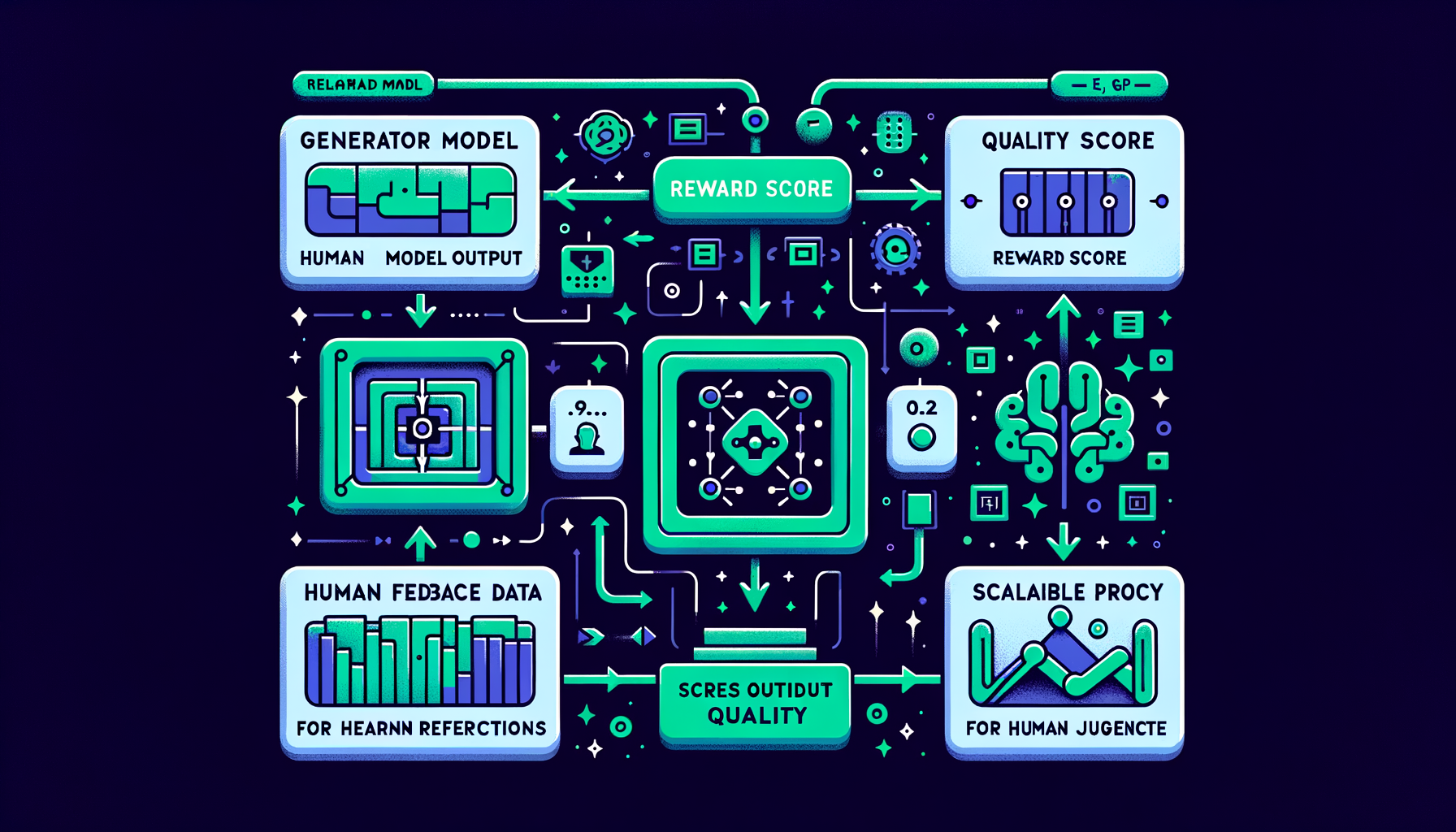
Reward modeling — learning human preferences at scale
A separate neural network trained to score any model output by quality, serving as a scalable automated proxy for human judgment.

RLHF — reinforcement learning from human feedback
Humans rank model outputs by quality; a reward model learns those preferences; the LLM is then optimized to maximize the learned reward signal.
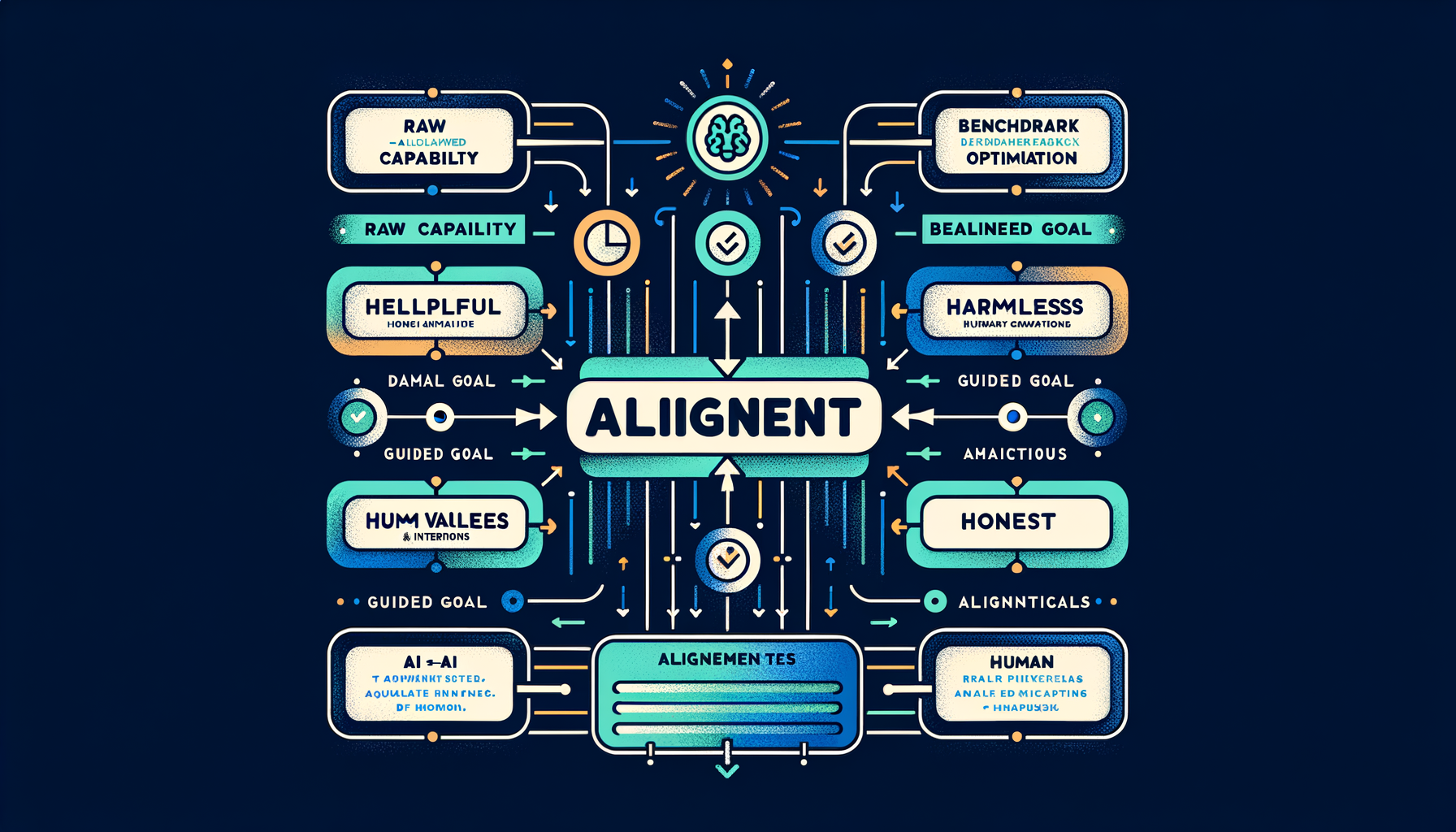
What is alignment — helpful, harmless, honest
The discipline of ensuring AI systems behave according to human values and intentions, not just optimize for raw capability on benchmarks.