Transformers
16 episodes — 90-second audio overviews on transformers.
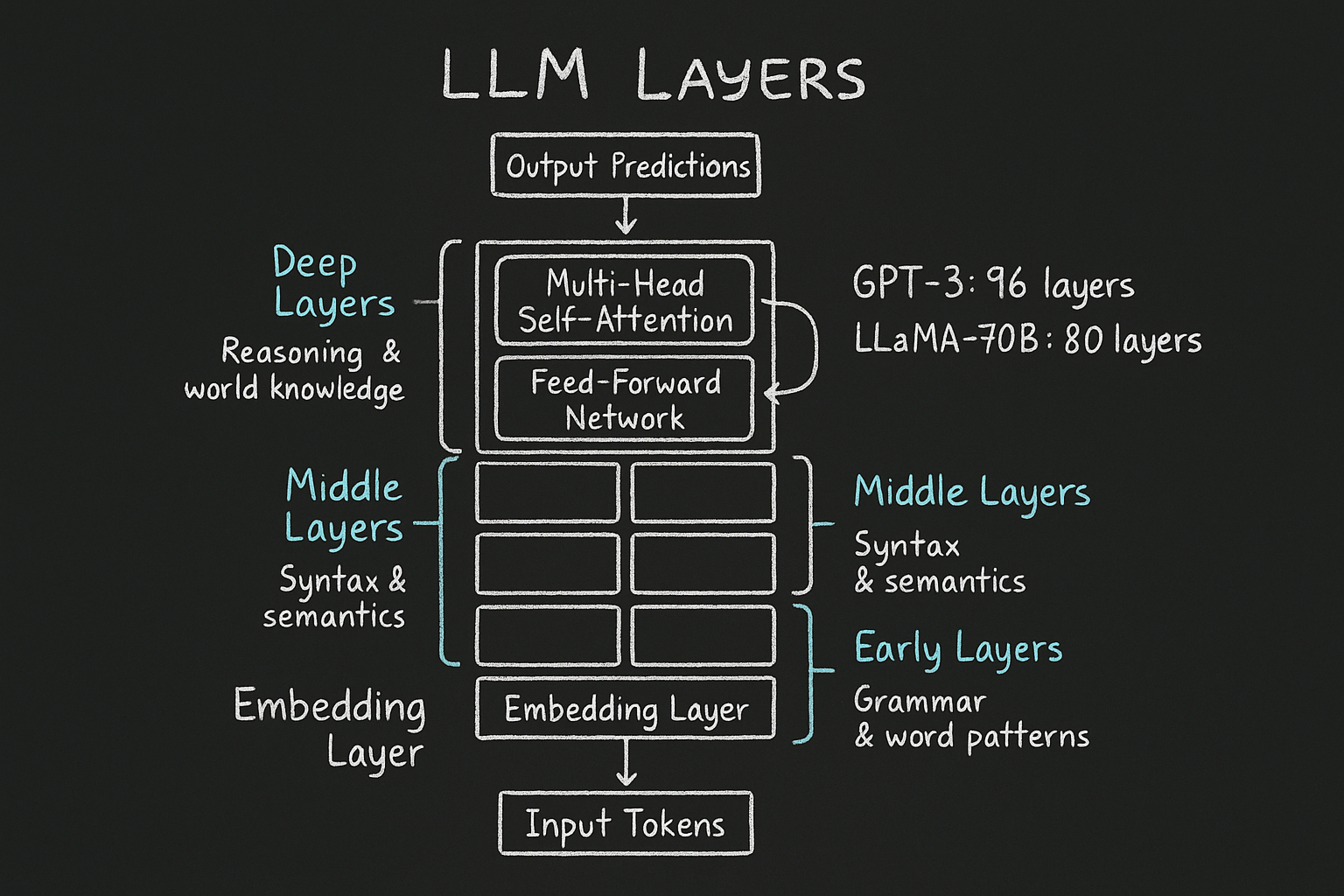
LLM layers — architecture of a large language model
A large language model is a deep stack of identical Transformer layers: early layers capture grammar, middle layers grasp semantics, and deep layers handle reasoning and world knowledge.
ALiBi & position extrapolation — extending context beyond training length
Adding position-dependent linear bias to attention scores, allowing models to handle sequences longer than their training context window.
Rotary Position Embeddings (RoPE) — modern position encoding
Encodes relative position by rotating Q/K vectors in pairs, enabling better generalization to sequence lengths not seen during training.

Sliding window attention — local context for efficiency
Each token only attends to a fixed window of nearby tokens instead of the full sequence, reducing cost from O(n²) to O(n·w).
Grouped-Query Attention (GQA) — the practical middle ground
Groups of heads share K/V projections (e.g., 8 groups for 32 heads), balancing quality retention with efficiency — the default in LLaMA 3 and Mistral.
Multi-Query Attention (MQA) — sharing K/V across all heads
All attention heads share a single set of key/value projections, dramatically reducing KV cache memory and boosting inference speed.
SwiGLU & modern activations — inside frontier transformers
SwiGLU replaces older ReLU in modern transformers (LLaMA, Mistral), providing smoother gradients and measurably better training dynamics.

The attention bottleneck — O(n²) cost of full attention
Attention scales quadratically with sequence length; a 100K-token input requires 10 billion attention pair computations per layer.

Causal masking — why decoders can't peek ahead
Future tokens are masked during training so each position only attends to past tokens, enabling left-to-right autoregressive generation.
Encoder vs decoder vs encoder-decoder
BERT uses an encoder (understanding), GPT uses a decoder (generation), T5 uses both — different configurations optimized for different GenAI tasks.
Residual connections & layer norm — stability for deep models
Skip connections add each sub-layer's input to its output, and normalization prevents values from exploding, enabling stable 100+ layer training.

Feed-forward networks — per-token transformation after attention
After attention mixes information across tokens, independent feed-forward layers transform each token's representation with nonlinear activation functions.
Multi-head attention — parallel perspectives on the same input
Multiple attention mechanisms run simultaneously, each learning to capture different relationship types like syntax, semantics, and coreference.

Query, Key, Value — the three vectors of attention
Tokens generate Q, K, V projections; attention scores come from Q·K dot-product similarity, and the output is V weighted by those scores.

Self-attention — every token looks at every other
Each token computes relevance scores against all other tokens, capturing long-range dependencies in a single parallel computation step.

The Transformer — the engine of modern GenAI
Published in 2017's "Attention Is All You Need," this architecture replaced recurrent networks and became the foundation of every frontier GenAI model.