Prompt Engineering
16 episodes — 90-second audio overviews on prompt engineering.
Coding benchmarks — HumanEval, SWE-bench, MBPP
Standard evaluations measuring code generation quality: from simple function completion (HumanEval) to resolving real GitHub issues (SWE-bench).
Repository-level code understanding — beyond single files
Models that navigate imports, call graphs, type systems, and project structure to generate contextually correct changes spanning multiple files.
Code execution feedback — running code to self-correct
Agents that generate code, execute it in a sandbox, read error messages, and iteratively fix bugs until all tests pass — closing the generate-test loop.

Code generation from natural language — describing what you want
Translating English descriptions into working functions, classes, and scripts — the core use case driving AI-assisted software development.
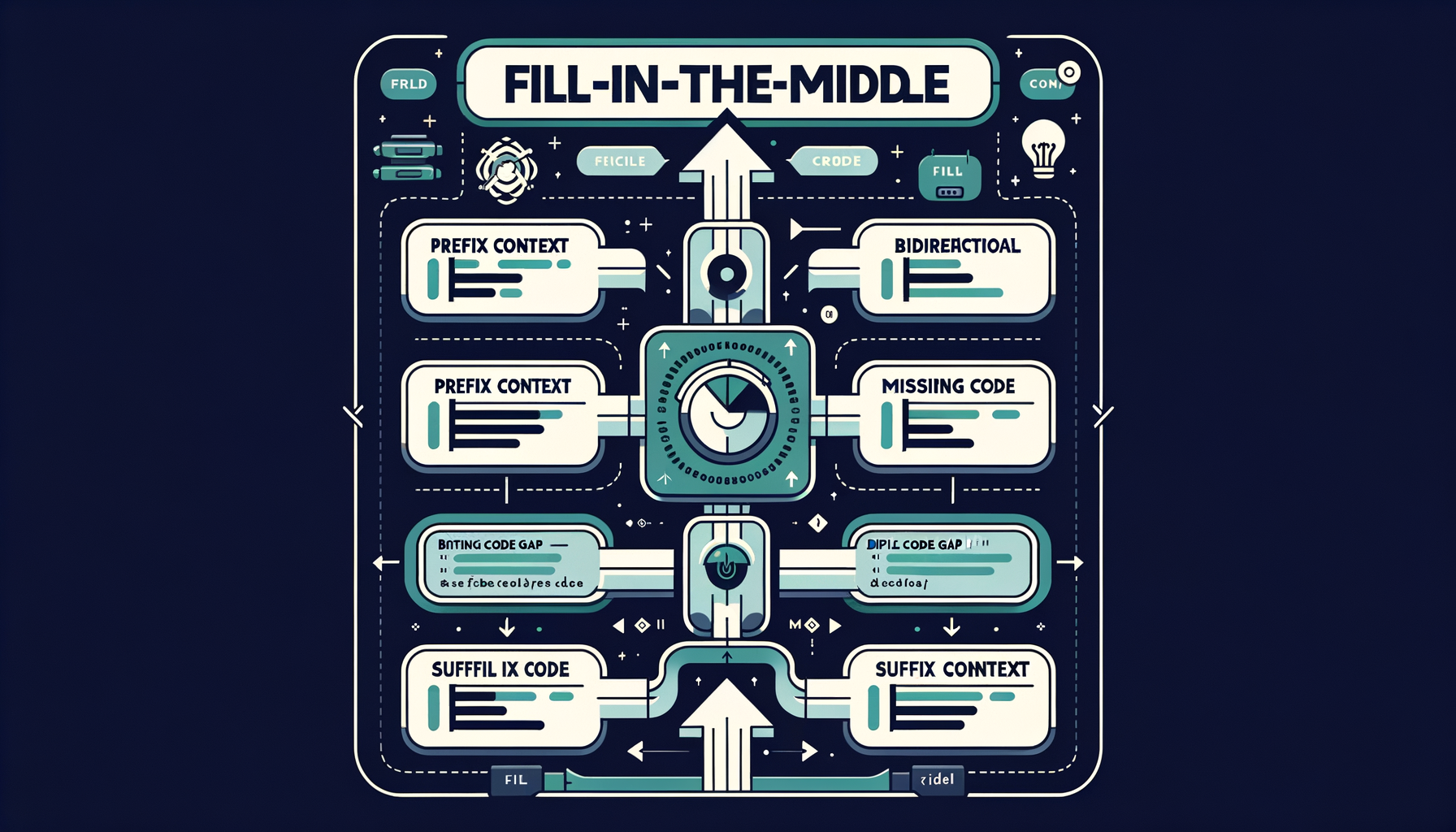
Fill-in-the-middle (FIM) — bidirectional code completion
Training models to predict missing code given both the prefix and suffix context, powering the inline autocomplete experience in editors like Copilot and Cursor.
Code LLMs — models specialized for programming
Codex, CodeLlama, StarCoder, DeepSeek Coder — models trained on massive code corpora that understand syntax, APIs, libraries, and programming patterns.
Meta-prompting — LLMs writing better prompts
Using one LLM to generate, evaluate, and iteratively optimize prompts for another model, automating the prompt engineering process itself.
Prompt chaining — multi-step workflows across prompts
Decomposing complex tasks into sequential prompt calls where each step's output feeds as context into the next step's input.

Structured output prompting — JSON and schema-constrained generation
Techniques and instructions that force LLM output into machine-parseable formats for reliable downstream integration with software systems.

Tree of Thoughts — branching solution exploration
The model generates multiple reasoning paths, evaluates each branch, and prunes bad directions — systematic search over the space of possible solutions.
ReAct — interleaving reasoning with action
A prompting framework where the model alternates between thinking about what to do (Reason), taking actions (tool calls), and processing observations.

Chain-of-thought (CoT) — step-by-step reasoning
Adding "Let's think step by step" or showing worked reasoning dramatically improves accuracy on math, logic, and multi-step problems.
Zero-shot prompting — instructions without examples
Relying entirely on the model's pre-trained knowledge and instruction tuning by providing only a clear, specific task description.
Few-shot prompting — teaching by example in context
Including 2-5 input/output examples directly in the prompt so the model infers the desired pattern and applies it to new inputs without any training.
System prompts — persistent behavioral instructions
Hidden instructions prepended to every conversation turn that define persona, rules, output format, tool access, and behavioral boundaries.

Prompt engineering — designing inputs for desired outputs
The practice of crafting structured prompts that reliably guide LLMs to produce accurate, well-formatted, and useful responses.