Large Language Models
18 episodes — 90-second audio overviews on large language models.
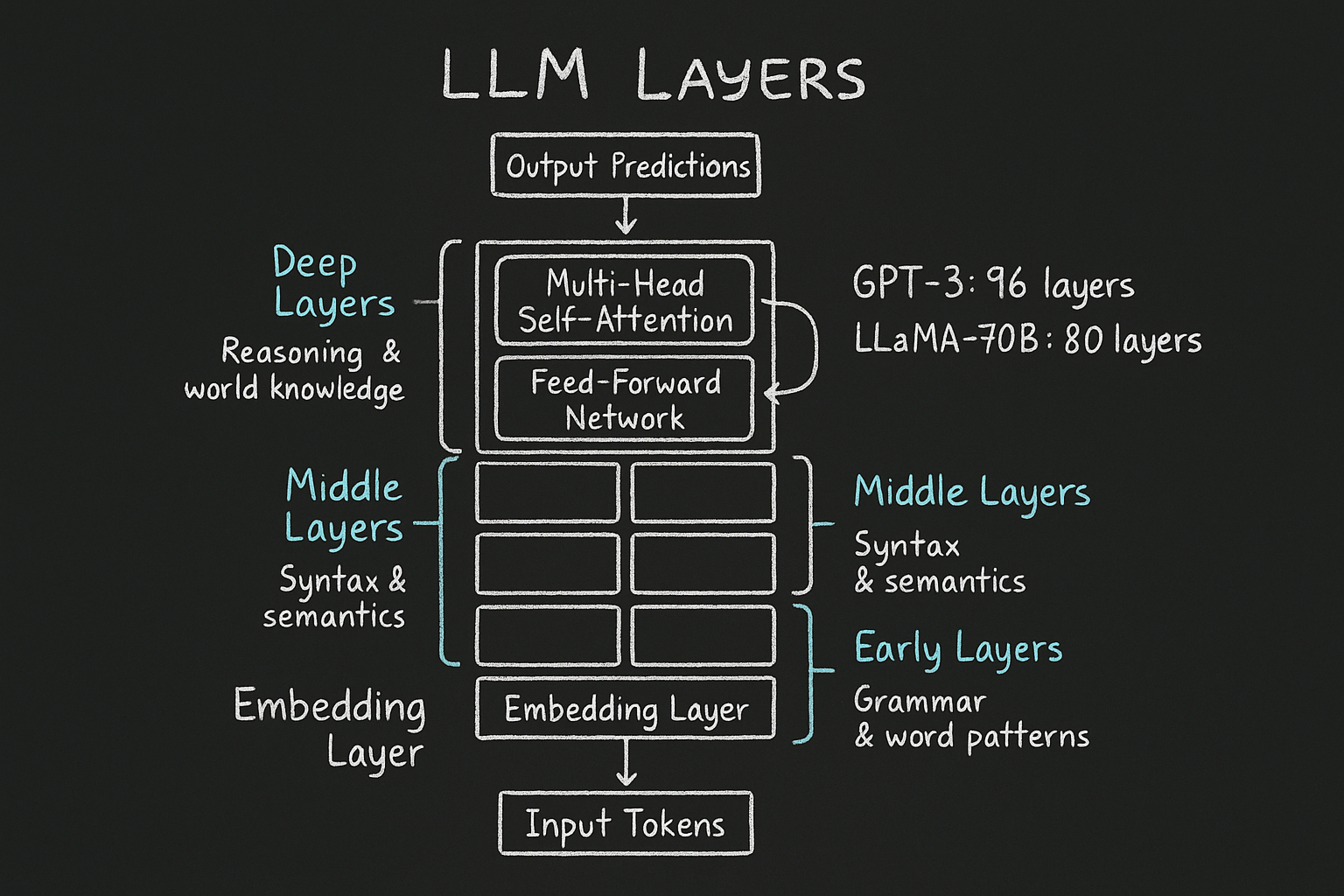
LLM layers — architecture of a large language model
A large language model is a deep stack of identical Transformer layers: early layers capture grammar, middle layers grasp semantics, and deep layers handle reasoning and world knowledge.

Training compute — measuring cost in FLOPs and GPU-hours
Frontier models cost $50-100M+ to train; understanding compute budgets frames what is feasible at different organizational scales.
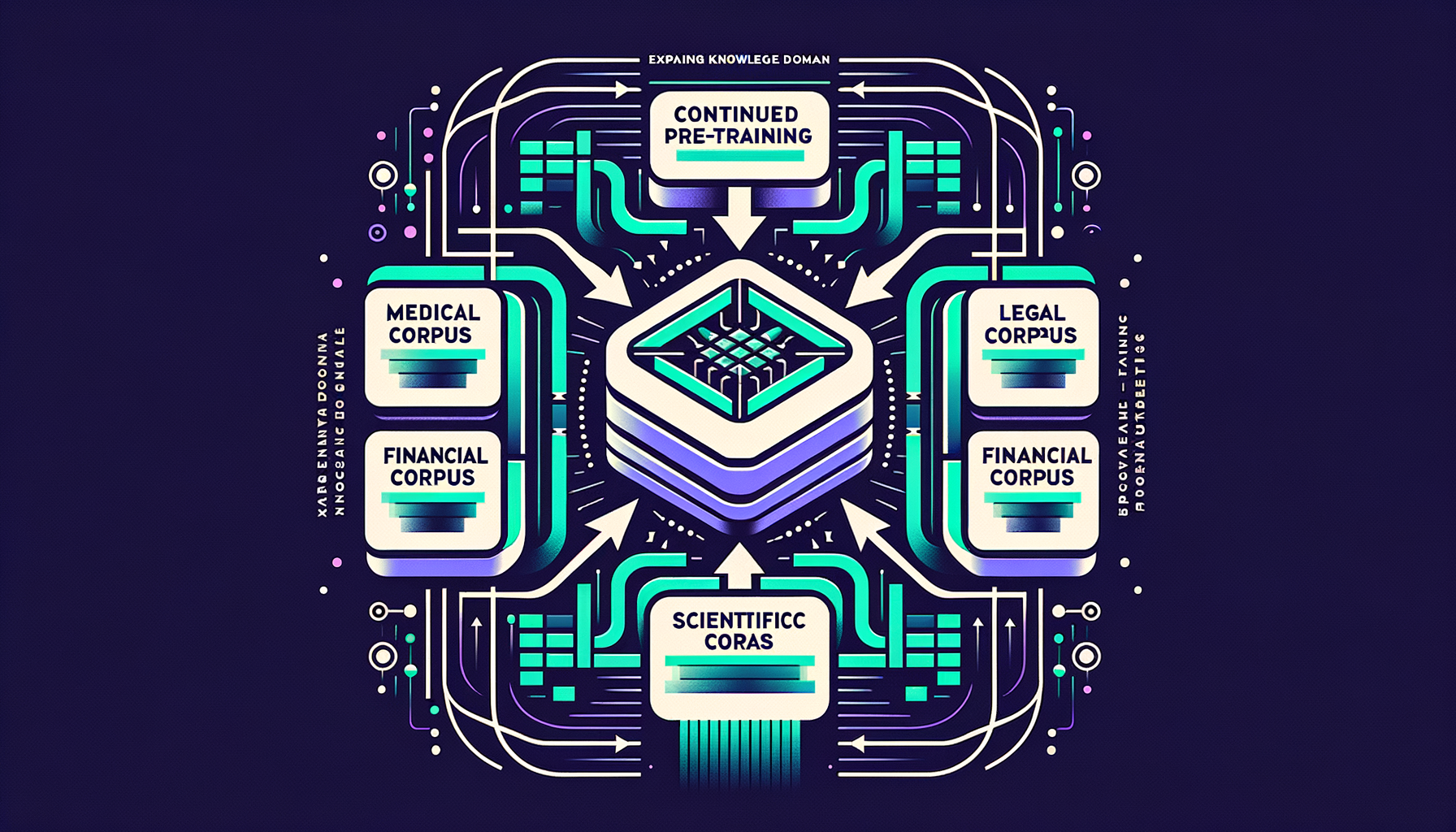
Continued pre-training — expanding a model's knowledge domain
Adding large domain-specific corpora (medical, legal, financial, scientific) to a base model to deepen expertise before fine-tuning.

Learning rate schedules — warming up and cooling down
Cosine decay with linear warmup is standard: gradually increase the learning rate at the start, then smoothly decrease it over the run.

Training loss curves — reading the heartbeat of pre-training
Smoothly decreasing loss means healthy training; spikes signal bad data batches, learning rate issues, or hardware failures.
Chinchilla optimal — balancing parameters and tokens
DeepMind's research showing that for a fixed compute budget, the optimal strategy scales data and parameters in roughly equal proportion.
Data mixture & weighting — balancing domains during training
The ratio of code, math, science, conversation, and books in training data directly shapes which capabilities the finished model develops.
Training data curation — filtering the internet for quality
Deduplication, toxicity filtering, domain balancing, quality scoring, and PII removal transform raw web crawls into effective training corpora.
The pre-training recipe — data, compute, and objectives
Curating trillions of tokens, allocating thousands of GPUs, and running next-token prediction for weeks to months at enormous cost.

Scaling laws — predictable performance from compute investment
Chinchilla and Kaplan laws show that model quality improves as a smooth power law function of parameters, data, and compute budget.
Emergent abilities — capabilities that appear at scale
Skills like in-context learning and multi-step reasoning that only manifest when models cross certain parameter/data thresholds.
Context window — the model's working memory
The maximum tokens processable in a single forward pass; ranges from 4K to 1M+ and directly limits what the model can reason about per request.
Next-token prediction — the deceptively simple training objective
Predicting the next token in a sequence: this single objective, applied at massive scale, produces reasoning, coding, and creative abilities.

Mistral & Mixtral — efficient European models
Mistral 7B and Mixtral 8x7B demonstrated that smaller, well-architected models (especially MoE) punch far above their parameter count.

Gemini — Google's natively multimodal family
Trained from the ground up on text, images, audio, and video, processing all modalities in a unified transformer architecture.

Claude — Anthropic's safety-first model family
Built with Constitutional AI and RLHF, emphasizing being helpful, harmless, and honest — proving alignment and capability can advance together.

GPT family — OpenAI's foundational lineage
From GPT-1 (117M params) to GPT-4 (rumored 1.8T MoE), the series that defined the modern LLM paradigm and launched the GenAI era.

What is an LLM — language models at billion-parameter scale
Transformer decoders with billions of parameters trained on trillions of tokens, exhibiting broad language understanding and generation capabilities.