Image Generation
16 episodes — 90-second audio overviews on image generation.
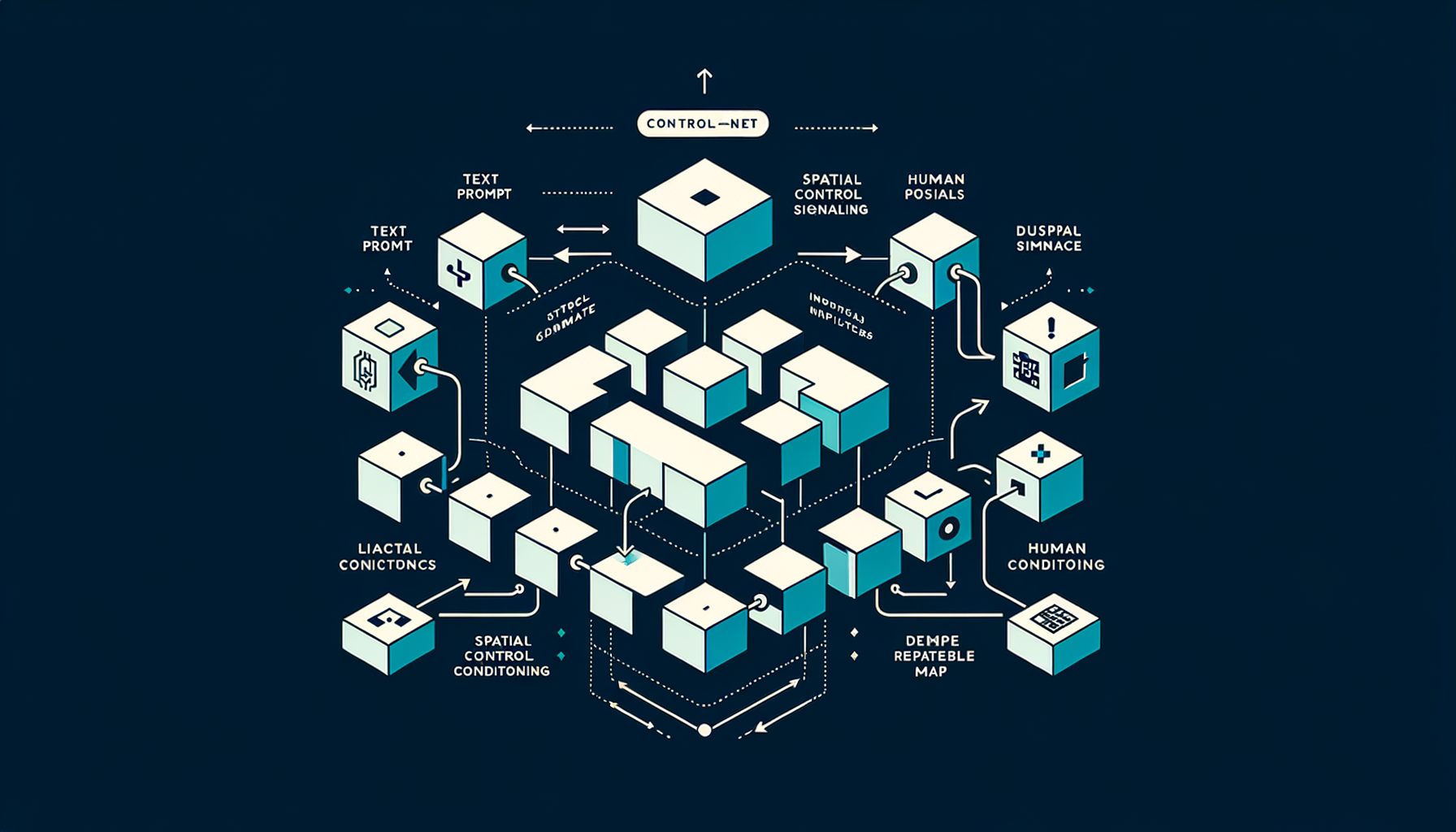
ControlNet — adding spatial conditioning
Injecting structural control signals (edge maps, human poses, depth maps) alongside text prompts for precise spatial layout control over the generated image.

Classifier-free guidance (CFG) — controlling prompt adherence
Blending conditional (text-guided) and unconditional predictions during generation; higher CFG values follow the text prompt more strictly at the cost of diversity.
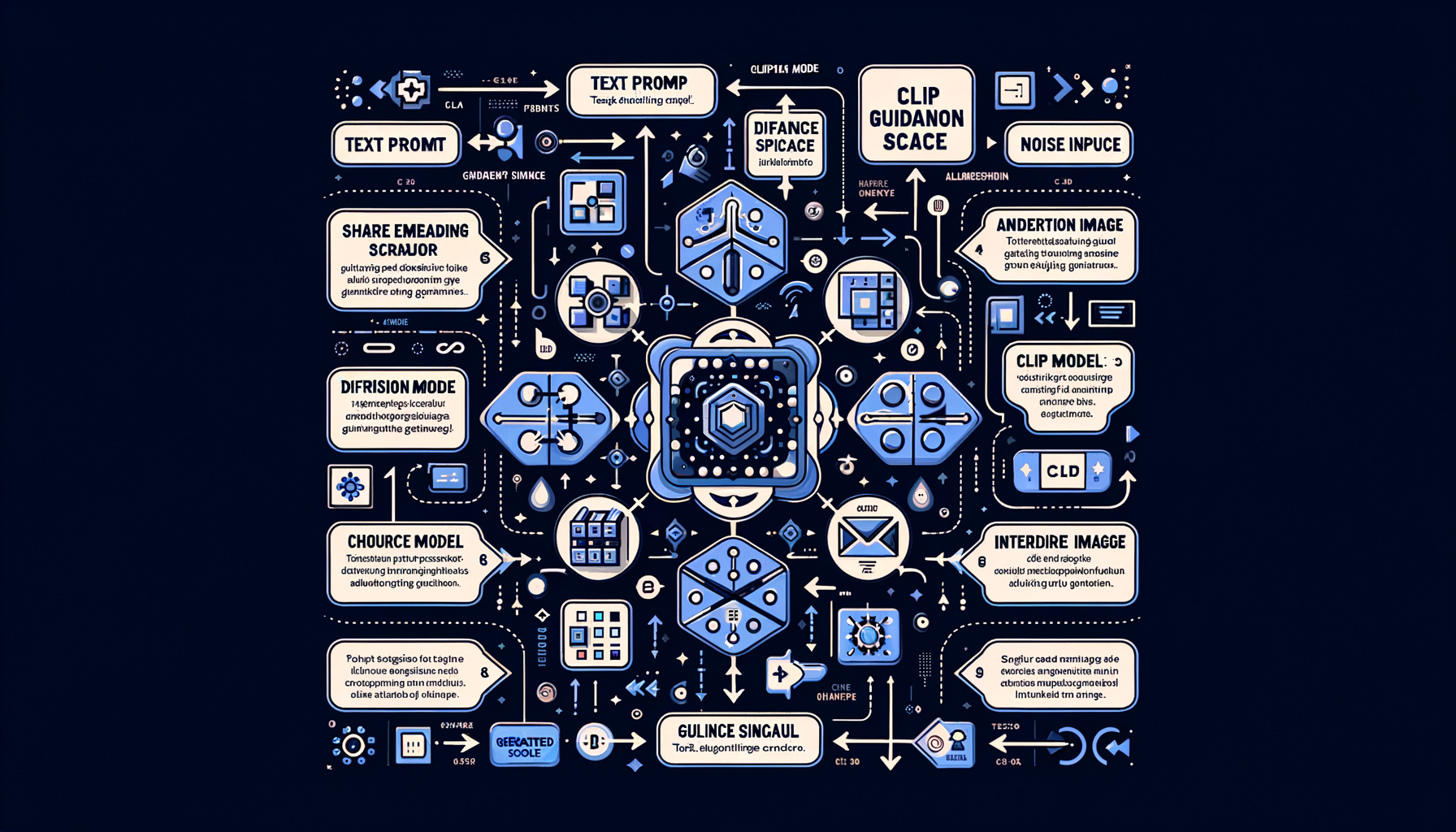
CLIP guidance — text-image alignment for generation
OpenAI's CLIP model provides a shared text-image embedding space that steers the diffusion process toward images matching a text description.
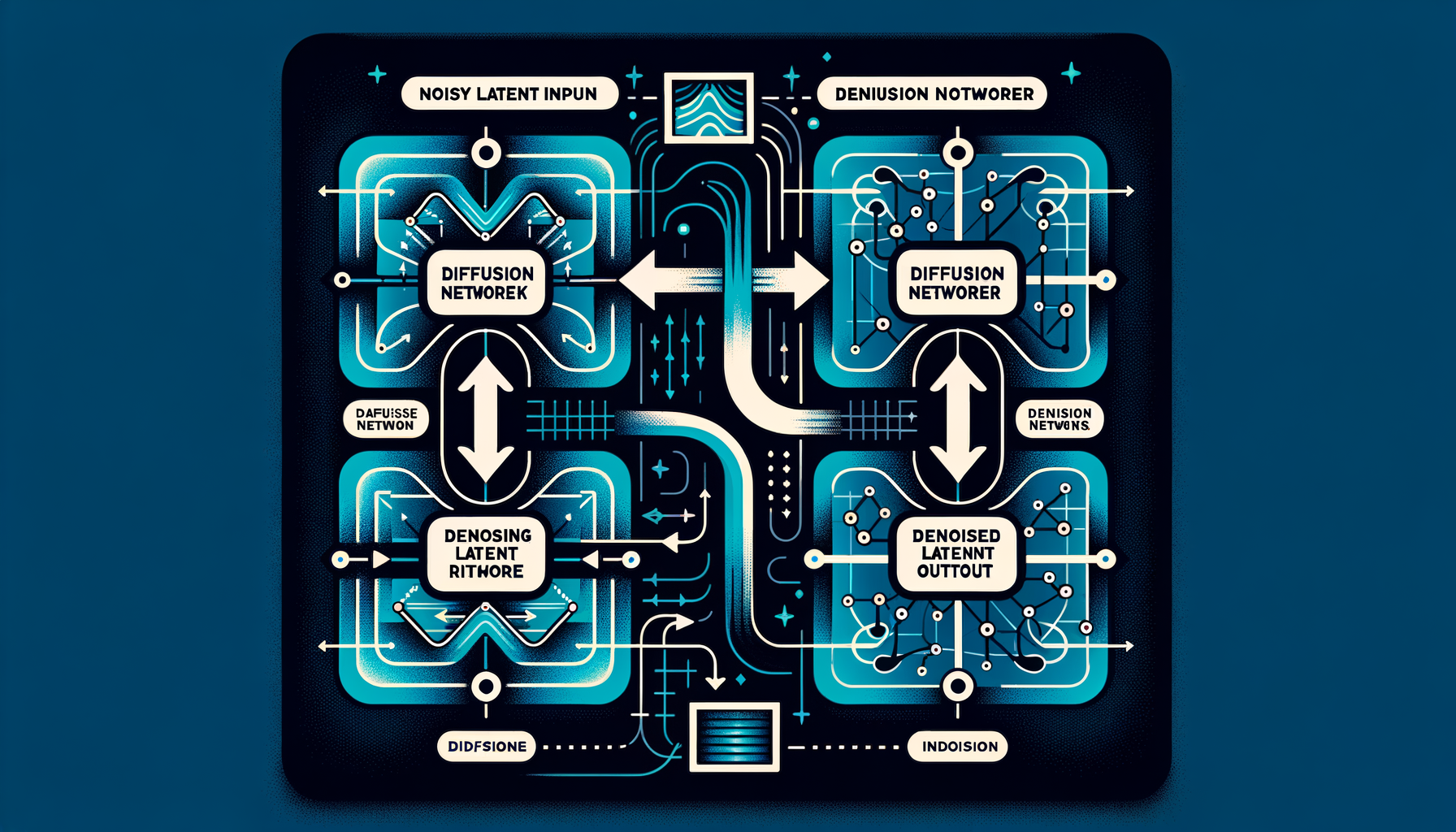
Diffusion Transformers (DiT) — replacing U-Net with transformers
Using transformer blocks instead of U-Net for the denoising network — powers Sora, Flux, and SD3, offering better scaling and quality at large sizes.
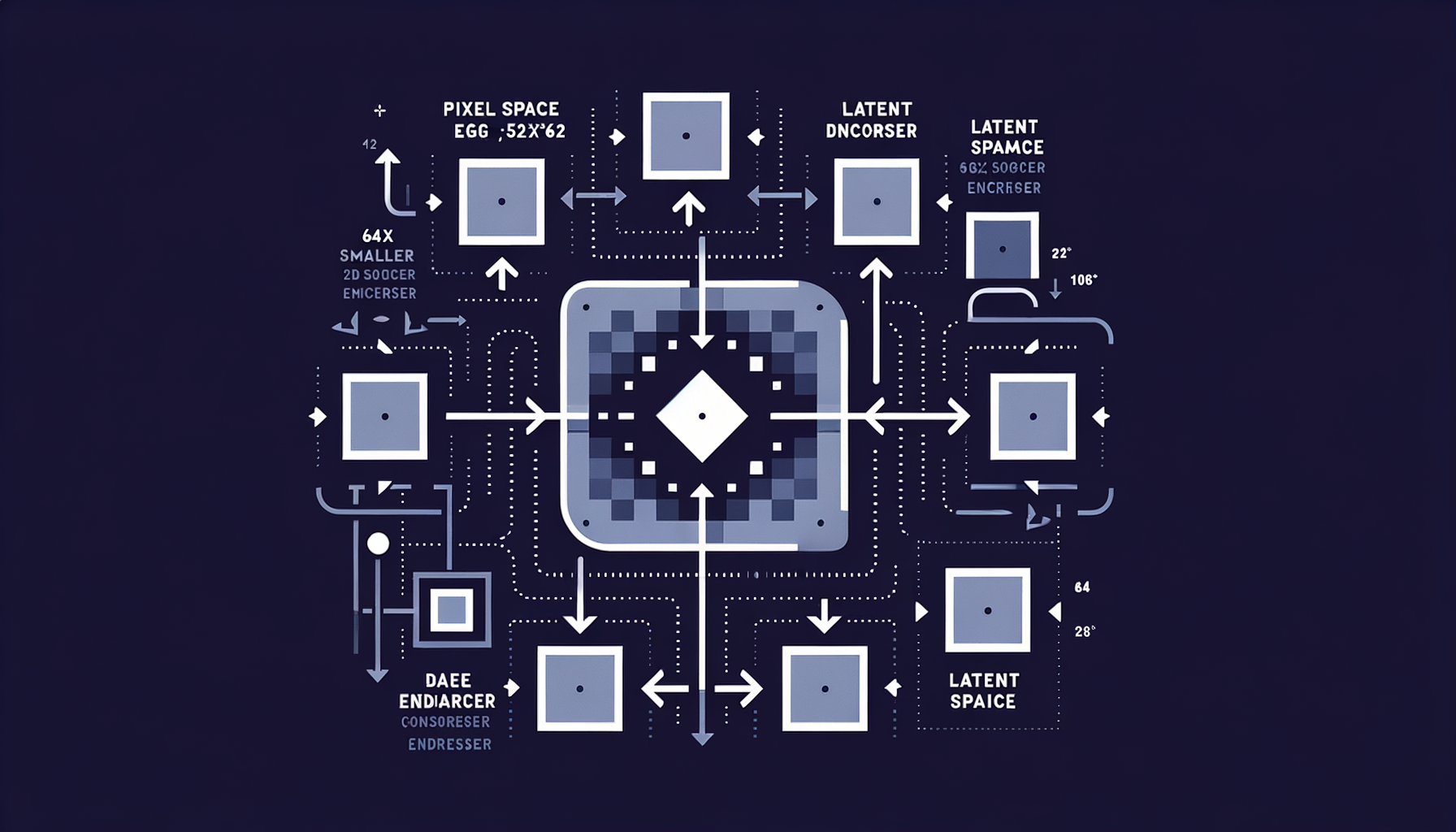
Latent diffusion — diffusing in compressed space
Running the diffusion process in a VAE's latent space (64x smaller than pixel space) rather than on raw pixels, making generation fast and memory-efficient.

U-Net — the denoising backbone
An encoder-decoder convolutional network with skip connections that predicts the noise to remove at each diffusion step — the workhorse architecture of Stable Diffusion 1.x and 2.x.

Noise schedules — controlling how noise is added
Linear, cosine, or learned schedules define how much noise is injected at each of the T timesteps — directly impacting generation quality and training stability.
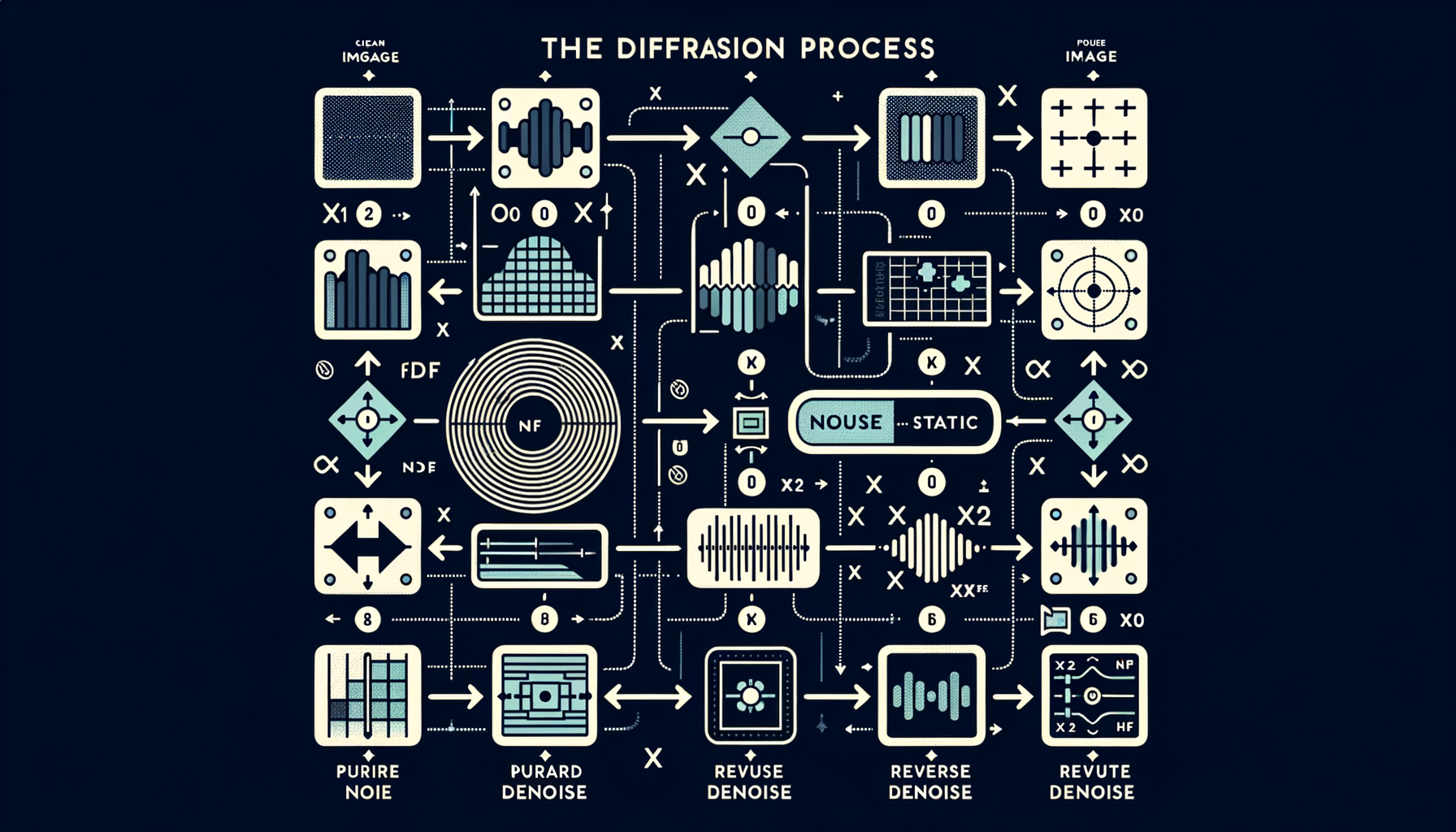
The diffusion process — forward noise, reverse denoise
Forward process: gradually add Gaussian noise over many steps until the image becomes pure static. Reverse process: learn to undo each step, recovering a clean image.

Why diffusion won — comparing generative architectures
Diffusion models offer stable training, mode coverage, better diversity, and higher fidelity than GANs, which is why they replaced GANs as the dominant approach for image and video generation.
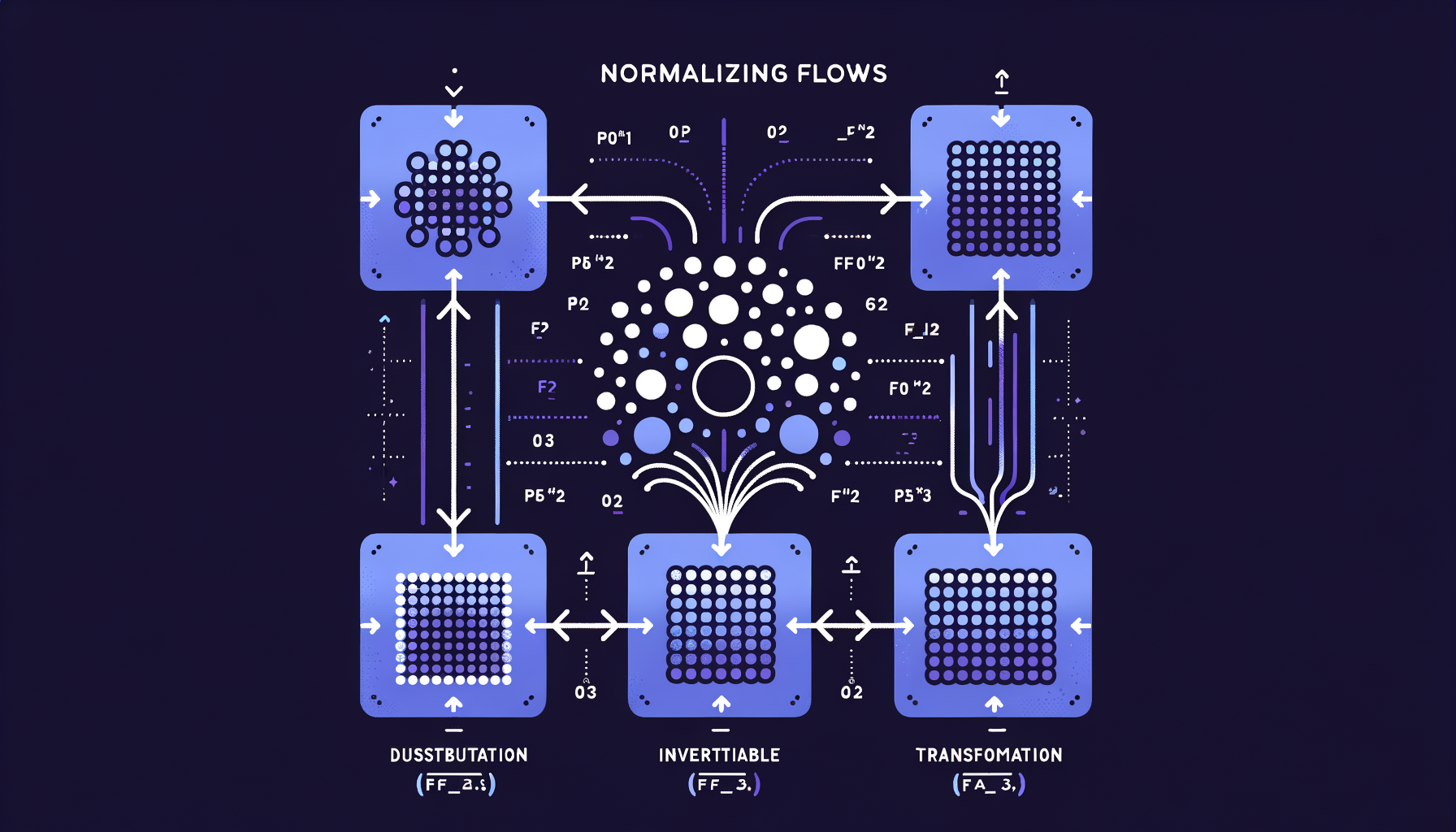
Normalizing Flows — invertible generation with exact likelihoods
Chains of invertible mathematical transformations that map simple distributions to complex ones, offering exact probability computation unlike GANs or VAEs.

GAN challenges — mode collapse and training instability
GANs are notoriously difficult to train: the generator may produce limited variety (mode collapse), and the adversarial balance is fragile and sensitive to hyperparameters.

GAN applications — StyleGAN, deepfakes, super-resolution
GANs powered photorealistic face generation (StyleGAN), image enhancement (ESRGAN), and synthetic media — the dominant GenAI paradigm before diffusion.
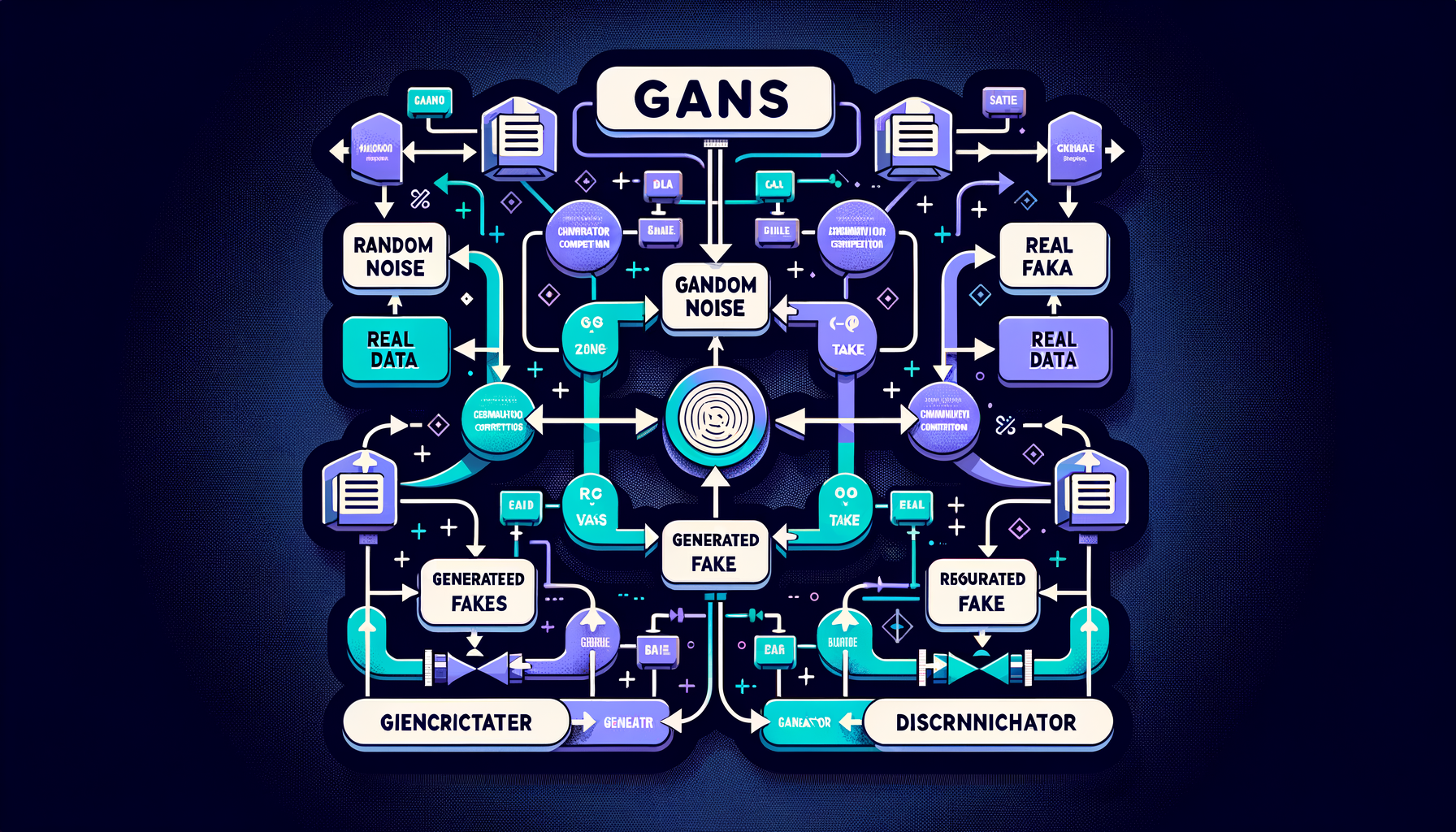
GANs — generator vs discriminator competition
Two networks in adversarial training: a generator creates fakes, a discriminator detects them — the competition drives both to improve, producing increasingly realistic outputs.
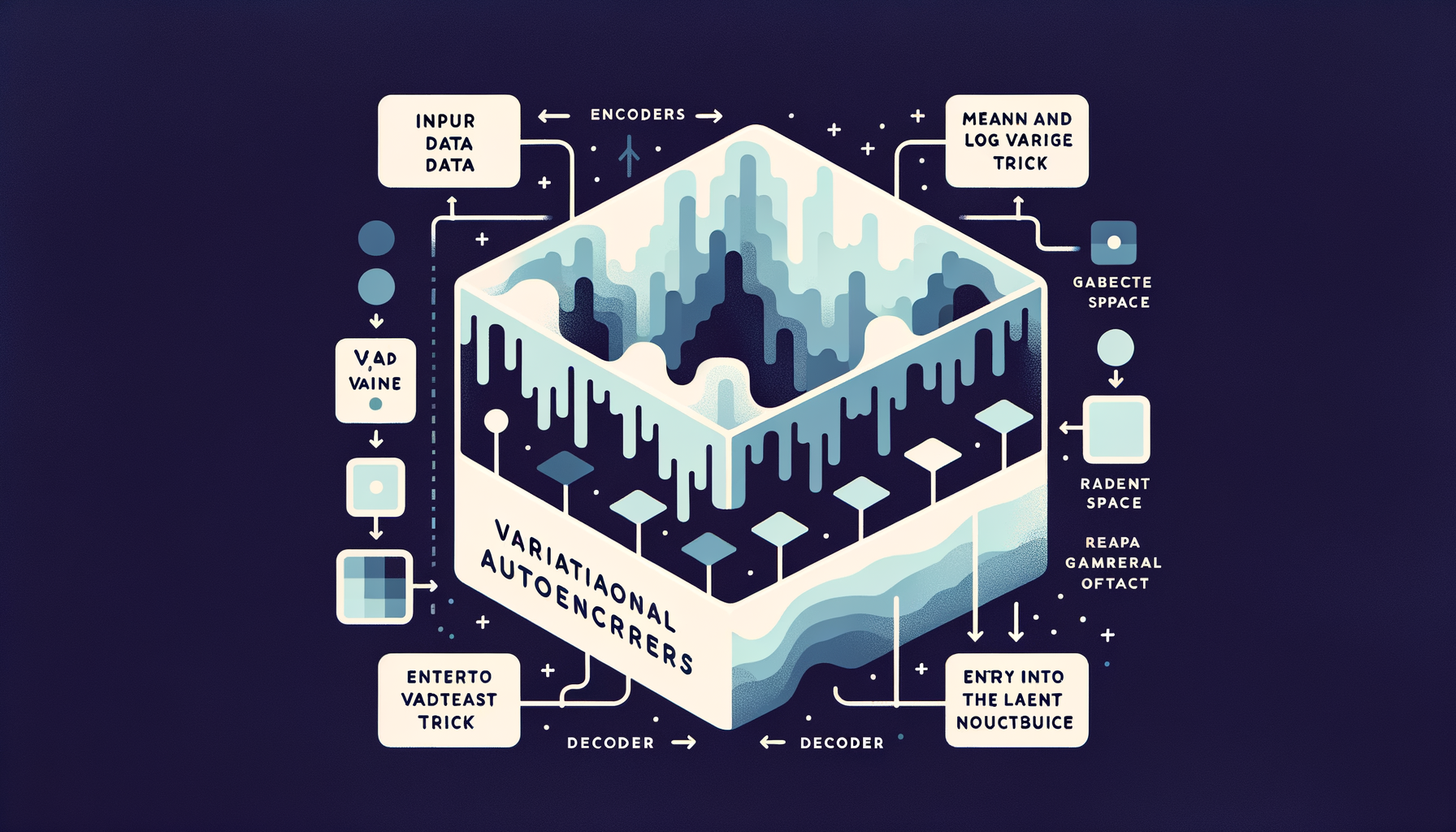
Variational Autoencoders (VAEs) — generating from learned distributions
Unlike basic autoencoders, VAEs encode inputs as probability distributions, enabling smooth interpolation between examples and sampling of entirely new outputs.

Latent space — the compressed world where generation happens
The bottleneck layer in an autoencoder where high-dimensional data (images, text) is compressed into a dense, navigable, lower-dimensional representation.

Autoencoders — compressing and reconstructing data
Neural networks that learn to encode input into a compact bottleneck representation and decode it back — the architectural foundation of latent space.