All Topics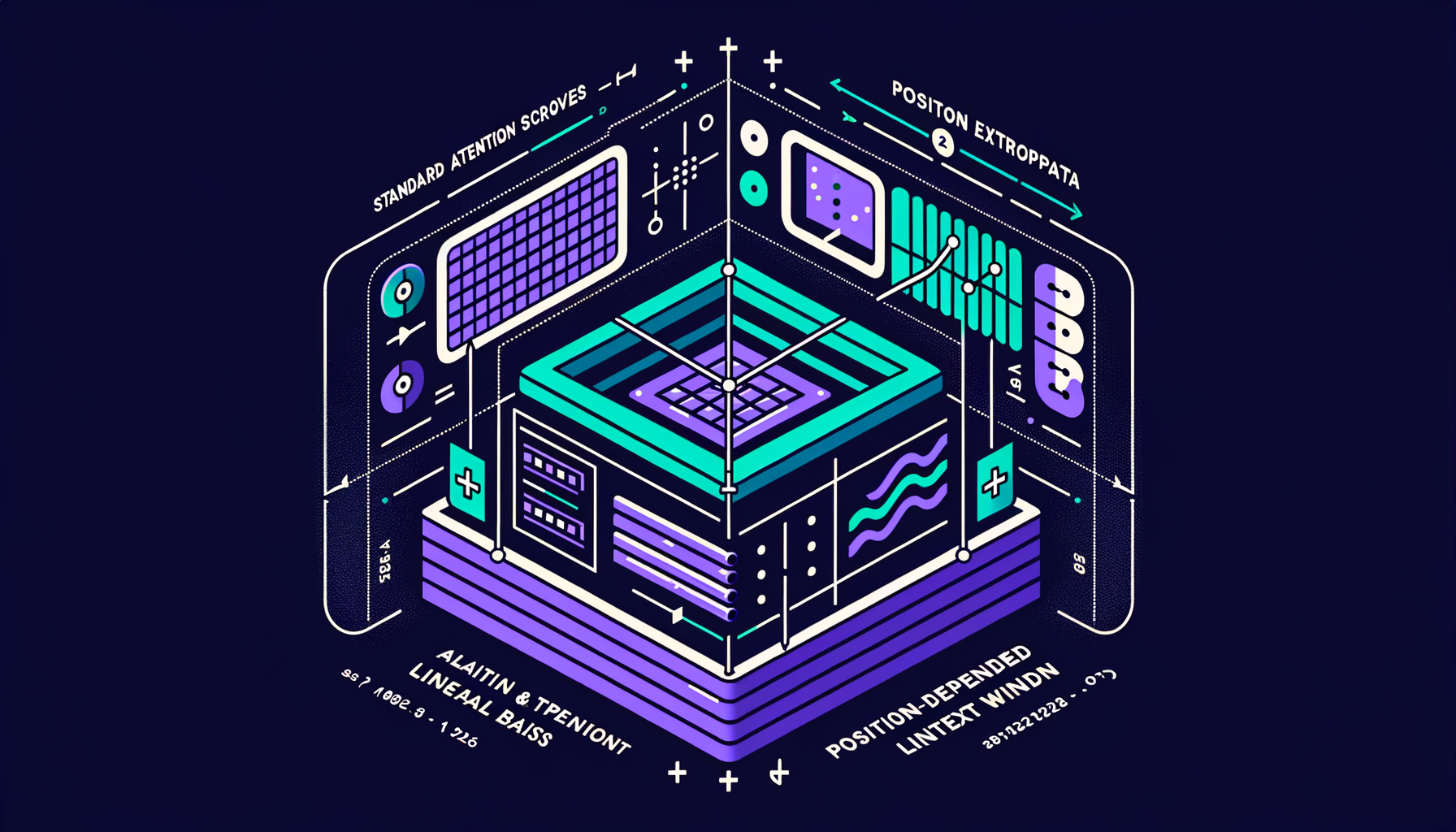

Attention Mechanism
5 episodes — 90-second audio overviews on attention mechanism.
1:34
ALiBi & position extrapolation — extending context beyond training length
Adding position-dependent linear bias to attention scores, allowing models to handle sequences longer than their training context window.
Attention MechanismTransformersGenerative AIGenAI Explained2026-02-18
1:18
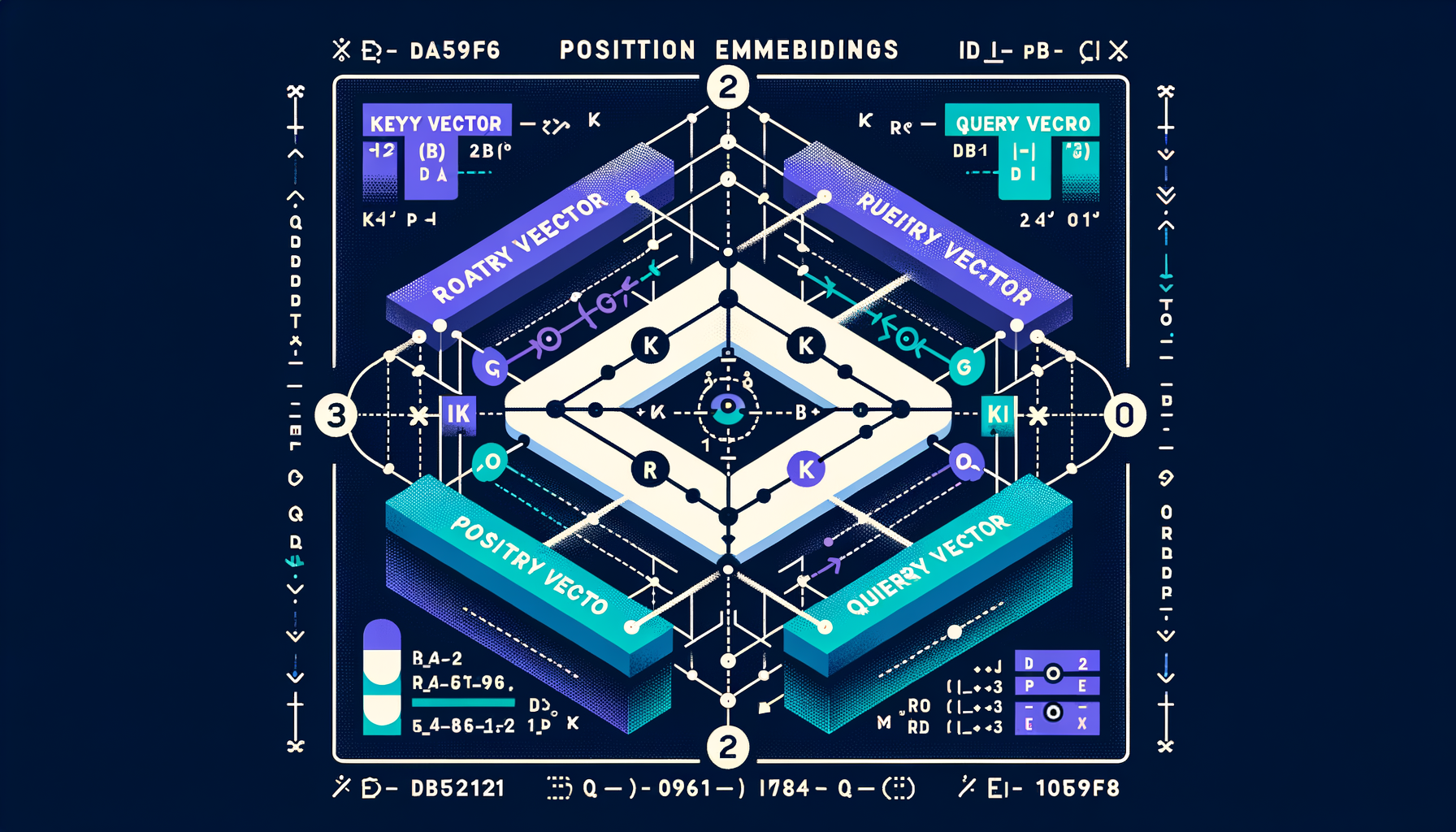
Rotary Position Embeddings (RoPE) — modern position encoding
Encodes relative position by rotating Q/K vectors in pairs, enabling better generalization to sequence lengths not seen during training.
Attention MechanismTransformersGenerative AIGenAI Explained2026-02-18
1:58
Sliding window attention — local context for efficiency
Each token only attends to a fixed window of nearby tokens instead of the full sequence, reducing cost from O(n²) to O(n·w).
Attention MechanismTransformersGenerative AIGenAI Explained2026-02-18
1:46
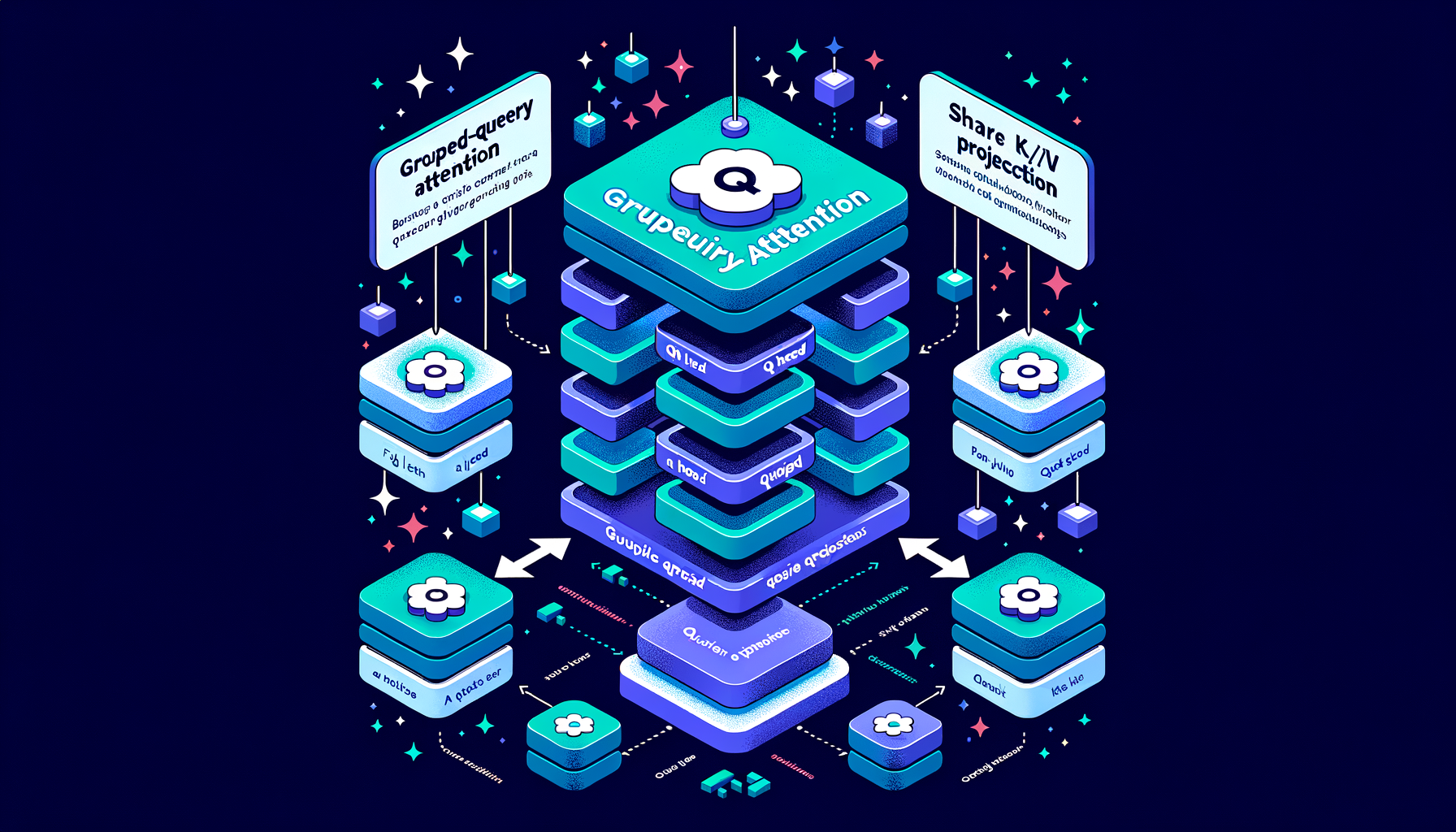
Grouped-Query Attention (GQA) — the practical middle ground
Groups of heads share K/V projections (e.g., 8 groups for 32 heads), balancing quality retention with efficiency — the default in LLaMA 3 and Mistral.
Attention MechanismTransformersGenerative AIGenAI Explained2026-02-18
1:49
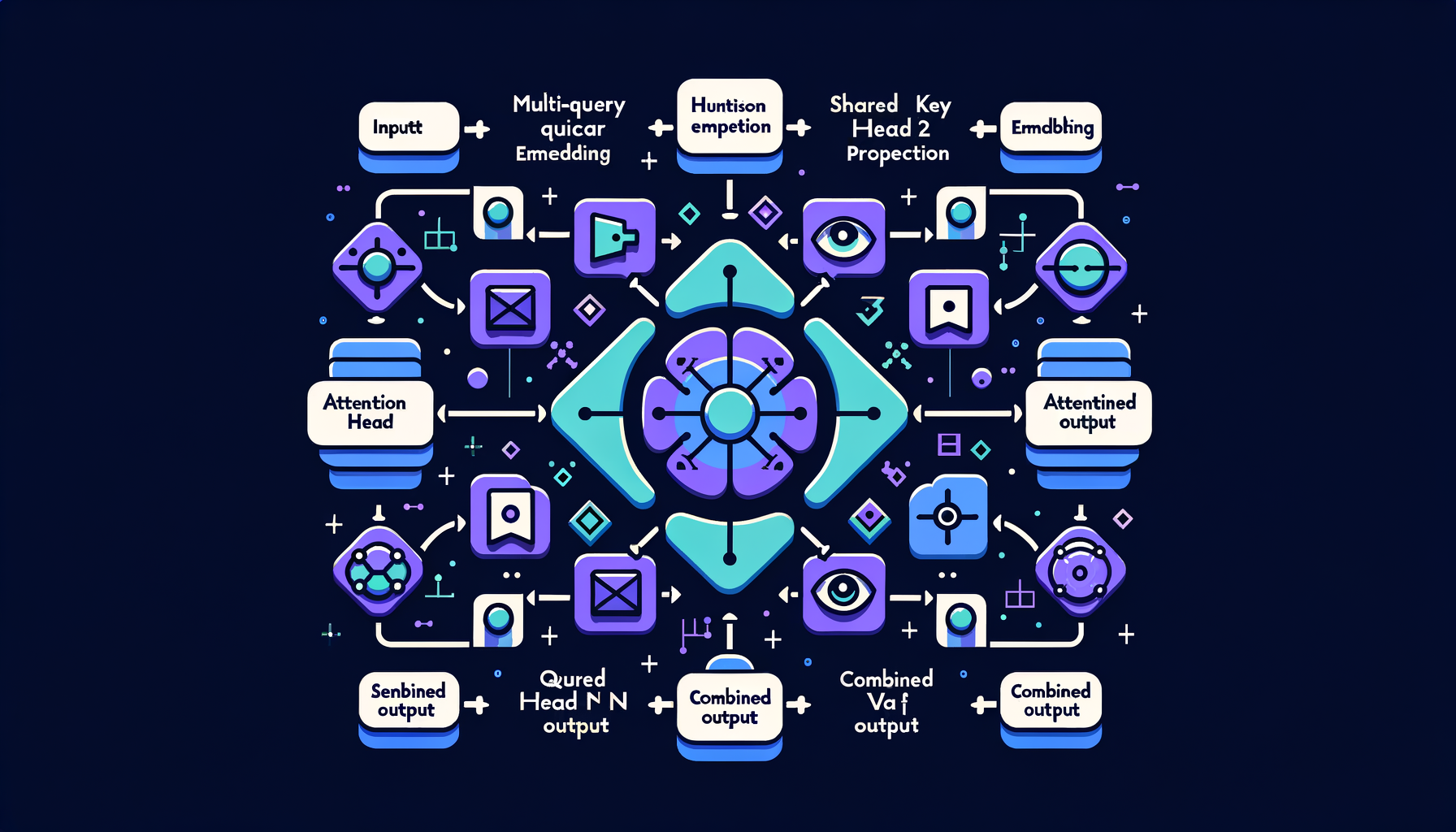
Multi-Query Attention (MQA) — sharing K/V across all heads
All attention heads share a single set of key/value projections, dramatically reducing KV cache memory and boosting inference speed.
Attention MechanismTransformersGenerative AIGenAI Explained2026-02-18