AI Safety
5 episodes — 90-second audio overviews on ai safety.
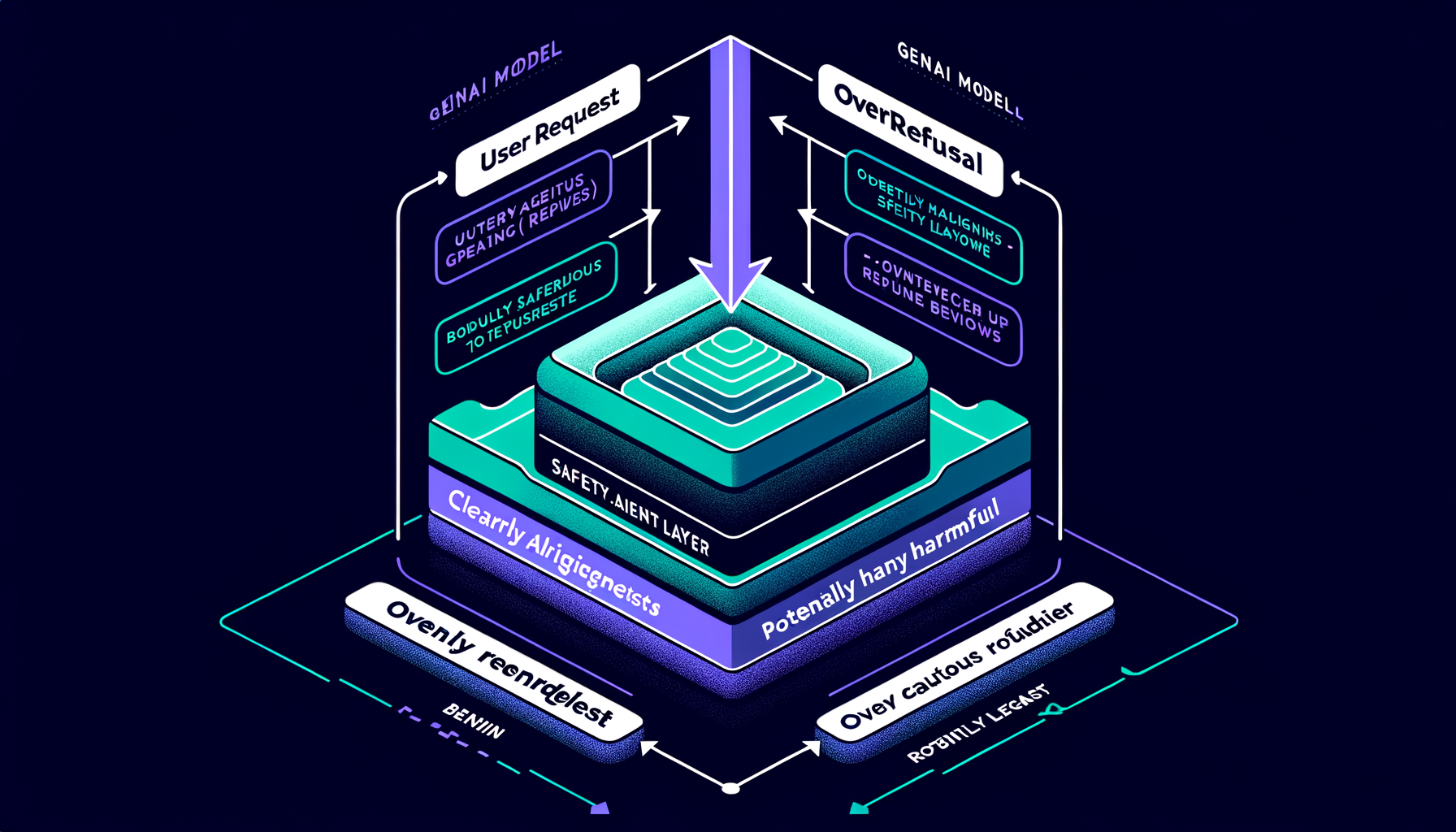
Overrefusal — when safety makes models too cautious
Excessive safety training causes refusal of clearly benign requests; calibrating the refusal boundary without compromising safety is a key alignment challenge.
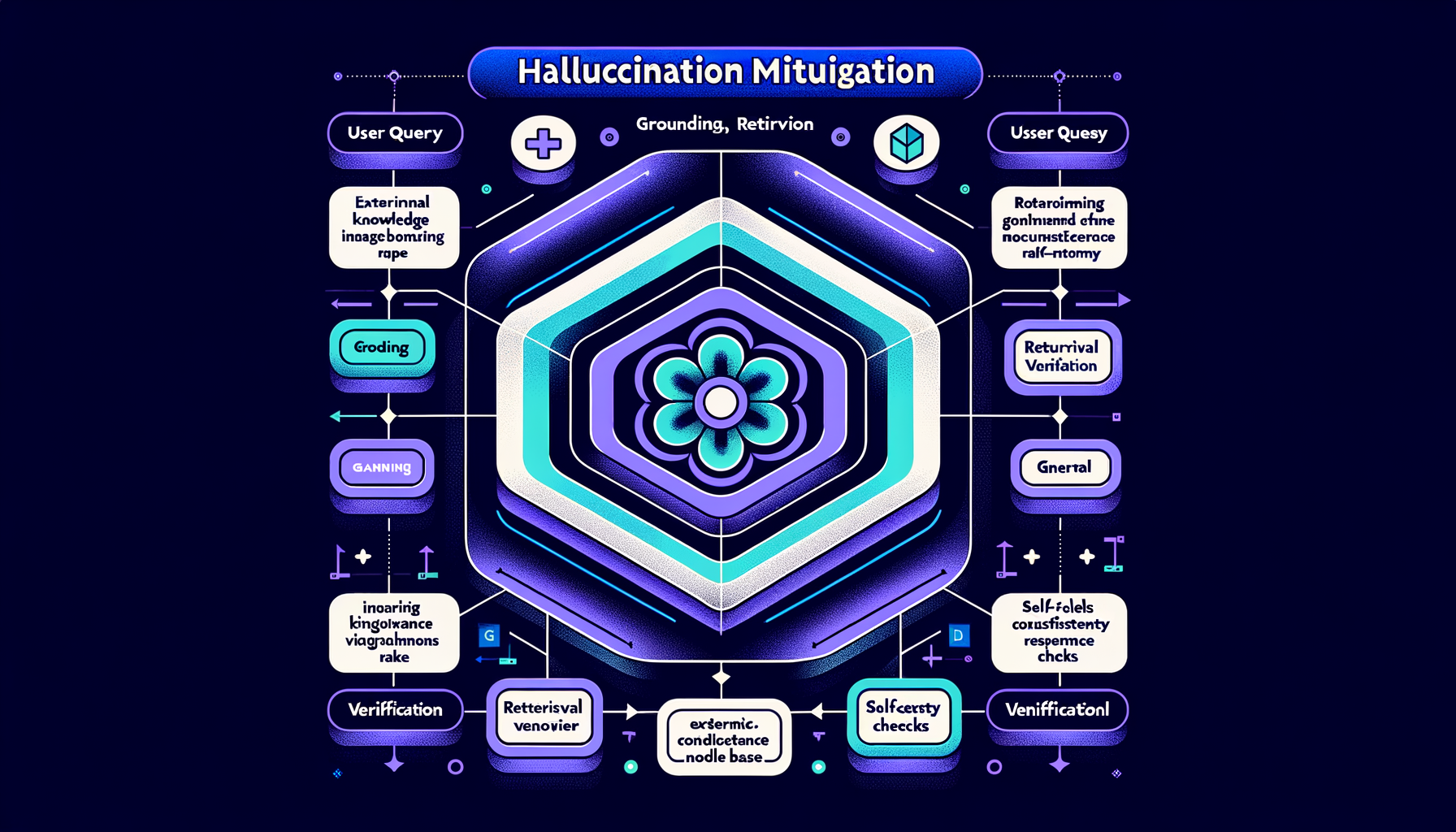
Hallucination mitigation — grounding, retrieval, verification
RAG, self-consistency checks, citation requirements, confidence calibration, and retrieval verification reduce but never fully eliminate hallucination.
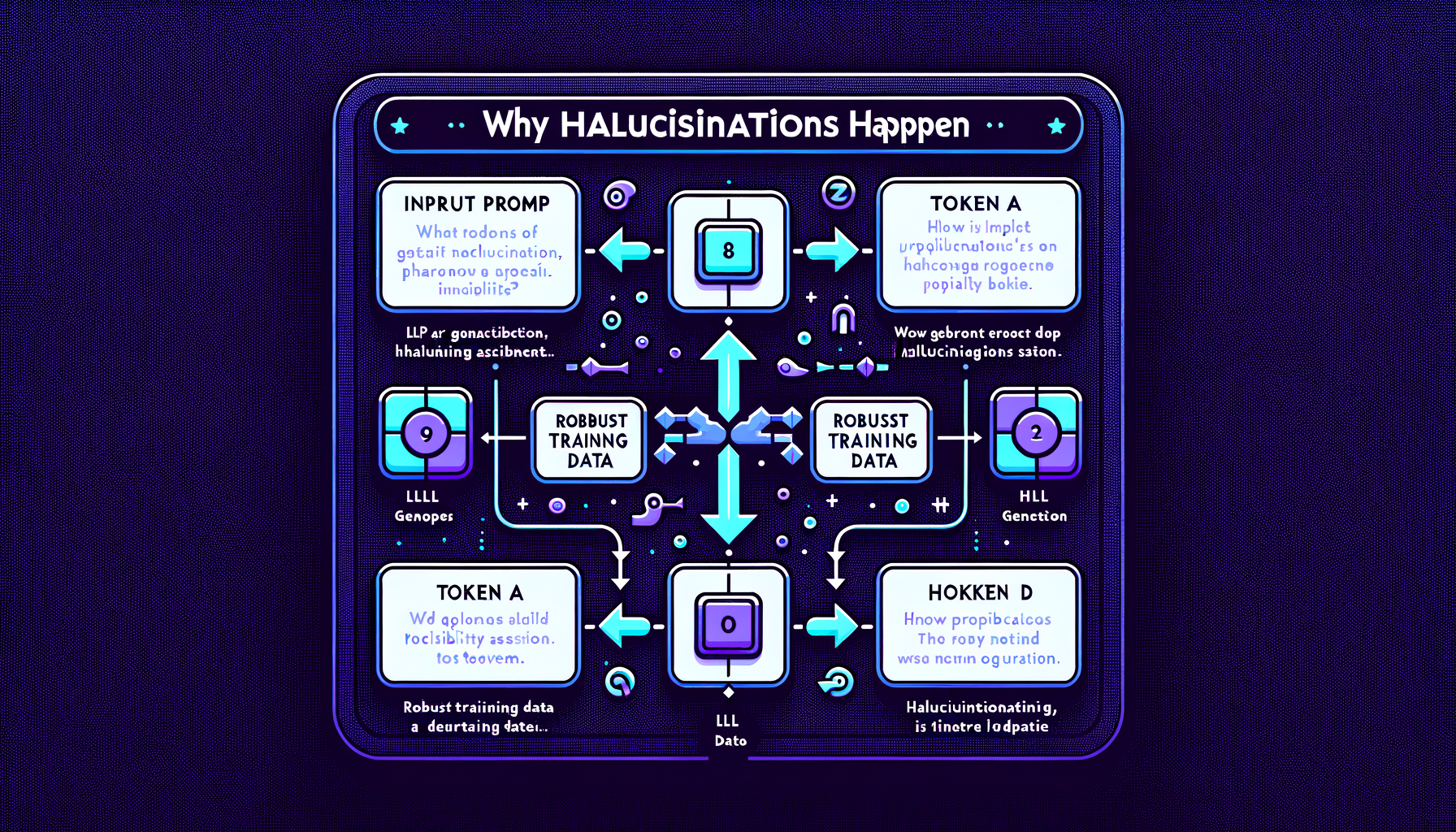
Why hallucinations happen — probability meets knowledge gaps
Models assign probability to all possible tokens including wrong ones; gaps in training data and distributional shift make some fabrication inevitable.

Types of hallucination — intrinsic vs extrinsic
Intrinsic hallucinations contradict the provided input; extrinsic hallucinations add unsupported claims from parametric memory — both undermine user trust.

Hallucination — when GenAI confidently fabricates information
Models generate plausible but factually wrong content because they optimize for fluency and pattern completion, not truth or accuracy.