AI Inference
11 episodes — 90-second audio overviews on ai inference.

Streaming & SSE — delivering tokens as they generate
Server-Sent Events push each token to the client immediately as it's produced, creating the live typing experience users expect from chat interfaces.
Structured decoding — constraining output to valid formats
Grammar-based or JSON-schema-based constraints that guarantee output is syntactically valid JSON, SQL, XML, or other structured formats.

Logit bias — steering toward or away from specific tokens
Manually adjusting individual token log-probabilities before sampling to encourage or suppress particular words, formats, or languages.
Stop sequences — controlling when generation halts
Defined strings or token IDs that trigger immediate generation termination, giving precise programmatic control over output boundaries.

Repetition penalty — preventing degenerate loops
Reducing the probability of recently generated tokens to avoid the repetitive patterns that plague naive decoding strategies.
Beam search — exploring multiple generation paths
Maintaining the k highest-probability partial sequences at each step; produces higher-likelihood outputs but less diverse text than sampling.
Top-p (nucleus) sampling — dynamic probability cutoff
Tokens are included in the candidate set until their cumulative probability reaches threshold p, adapting the pool size to the model's confidence.

Top-k sampling — fixed-size candidate filtering
Only the k most probable next tokens are considered before sampling, filtering out the long tail of unlikely noise.

Temperature — controlling randomness in generation
A scaling factor applied to logits before softmax: temperature=0 always picks the top token (greedy), higher values spread probability across more candidates.
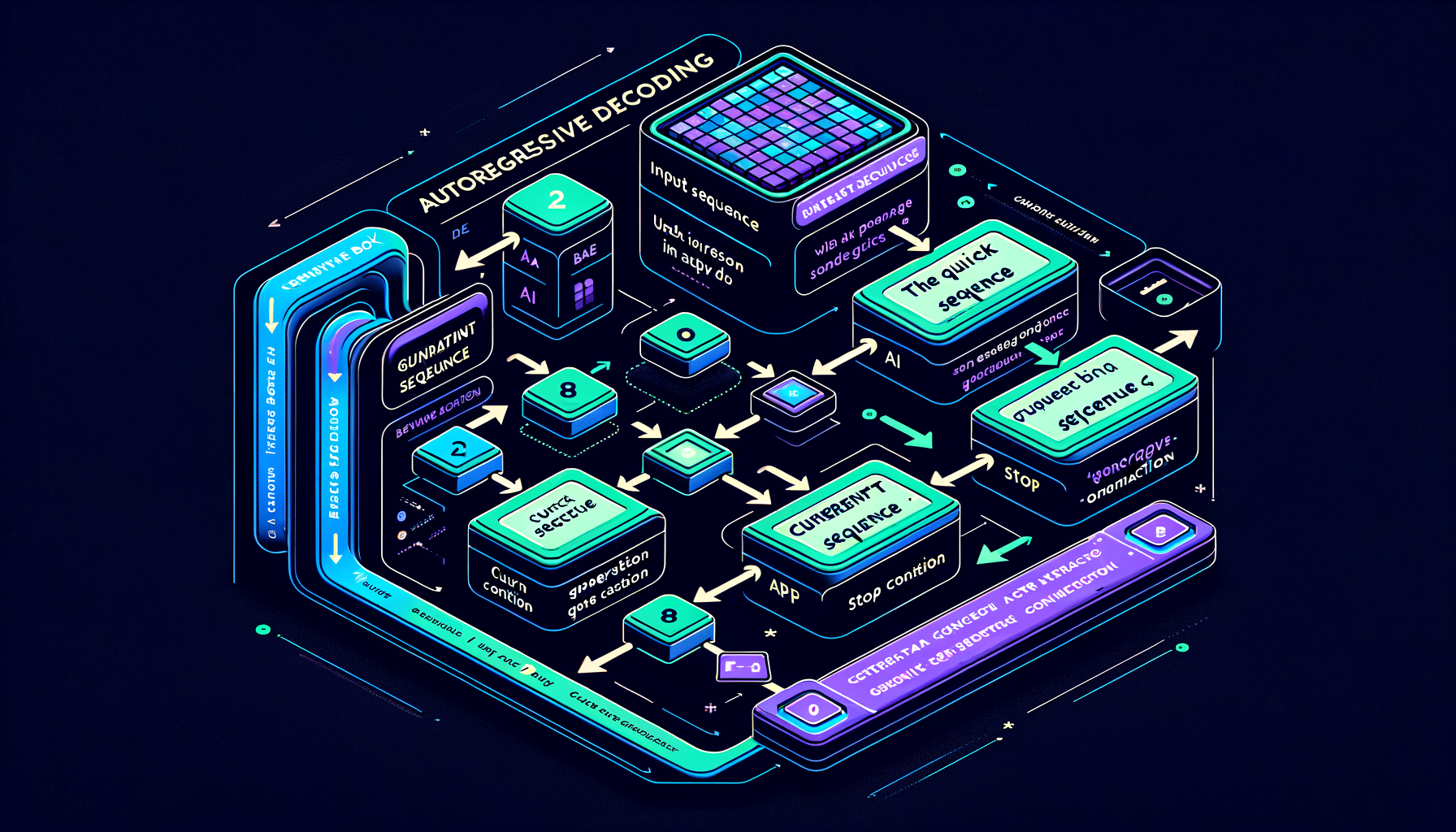
Autoregressive decoding — generating one token at a time
The model produces tokens sequentially, each conditioned on all previous tokens, until hitting a stop token or length limit.
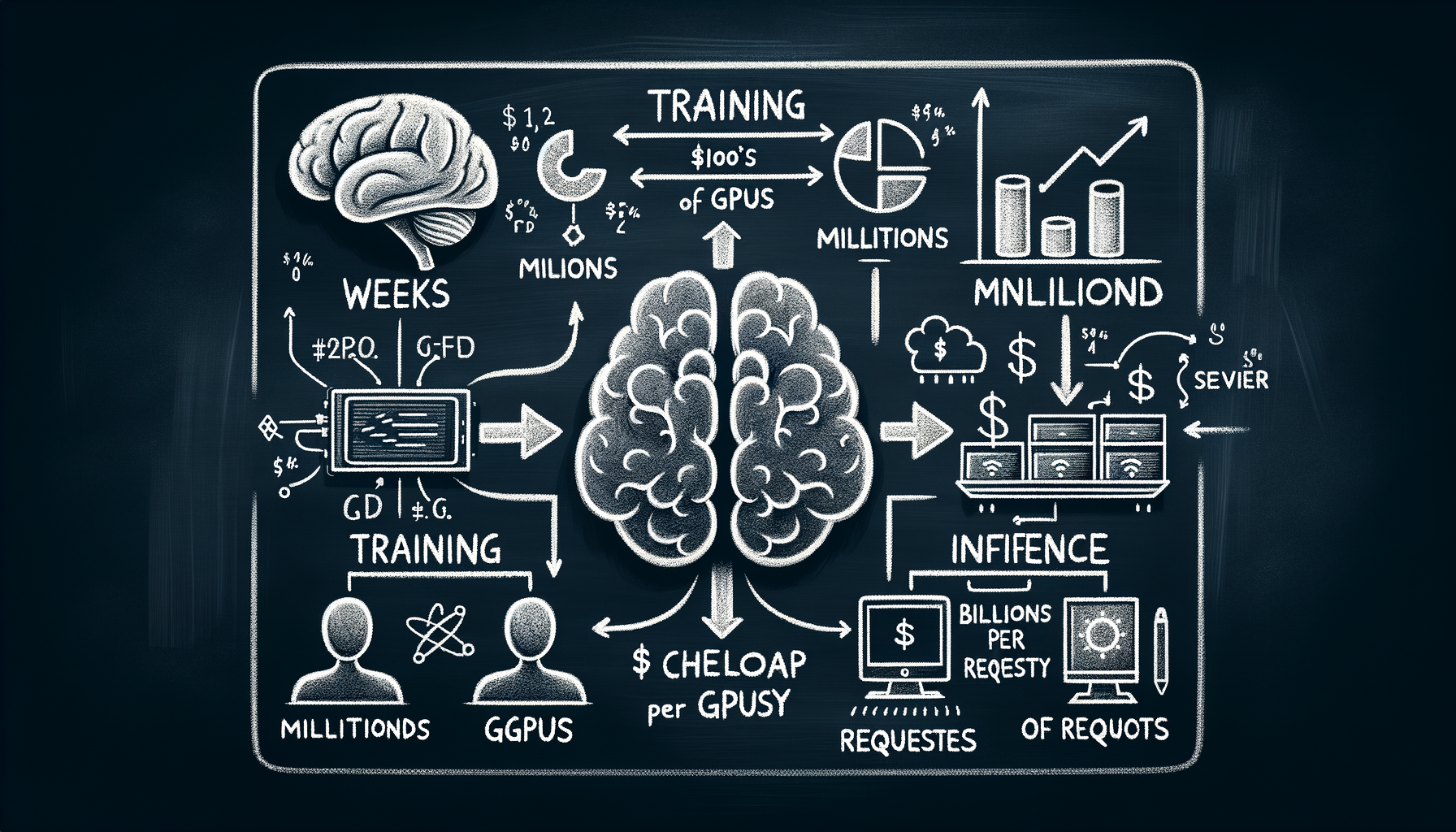
The training-inference split — building the brain vs using it
Training costs millions of dollars and takes weeks on thousands of GPUs; inference serves billions of requests cheaply — two fundamentally different engineering problems.