AI Basics
36 episodes — 90-second audio overviews on ai basics.

Why diffusion won — comparing generative architectures
Diffusion models offer stable training, mode coverage, better diversity, and higher fidelity than GANs, which is why they replaced GANs as the dominant approach for image and video generation.
Normalizing Flows — invertible generation with exact likelihoods
Chains of invertible mathematical transformations that map simple distributions to complex ones, offering exact probability computation unlike GANs or VAEs.

GAN challenges — mode collapse and training instability
GANs are notoriously difficult to train: the generator may produce limited variety (mode collapse), and the adversarial balance is fragile and sensitive to hyperparameters.

GAN applications — StyleGAN, deepfakes, super-resolution
GANs powered photorealistic face generation (StyleGAN), image enhancement (ESRGAN), and synthetic media — the dominant GenAI paradigm before diffusion.
GANs — generator vs discriminator competition
Two networks in adversarial training: a generator creates fakes, a discriminator detects them — the competition drives both to improve, producing increasingly realistic outputs.
Variational Autoencoders (VAEs) — generating from learned distributions
Unlike basic autoencoders, VAEs encode inputs as probability distributions, enabling smooth interpolation between examples and sampling of entirely new outputs.

Latent space — the compressed world where generation happens
The bottleneck layer in an autoencoder where high-dimensional data (images, text) is compressed into a dense, navigable, lower-dimensional representation.

Autoencoders — compressing and reconstructing data
Neural networks that learn to encode input into a compact bottleneck representation and decode it back — the architectural foundation of latent space.
SwiGLU & modern activations — inside frontier transformers
SwiGLU replaces older ReLU in modern transformers (LLaMA, Mistral), providing smoother gradients and measurably better training dynamics.

The attention bottleneck — O(n²) cost of full attention
Attention scales quadratically with sequence length; a 100K-token input requires 10 billion attention pair computations per layer.

Causal masking — why decoders can't peek ahead
Future tokens are masked during training so each position only attends to past tokens, enabling left-to-right autoregressive generation.
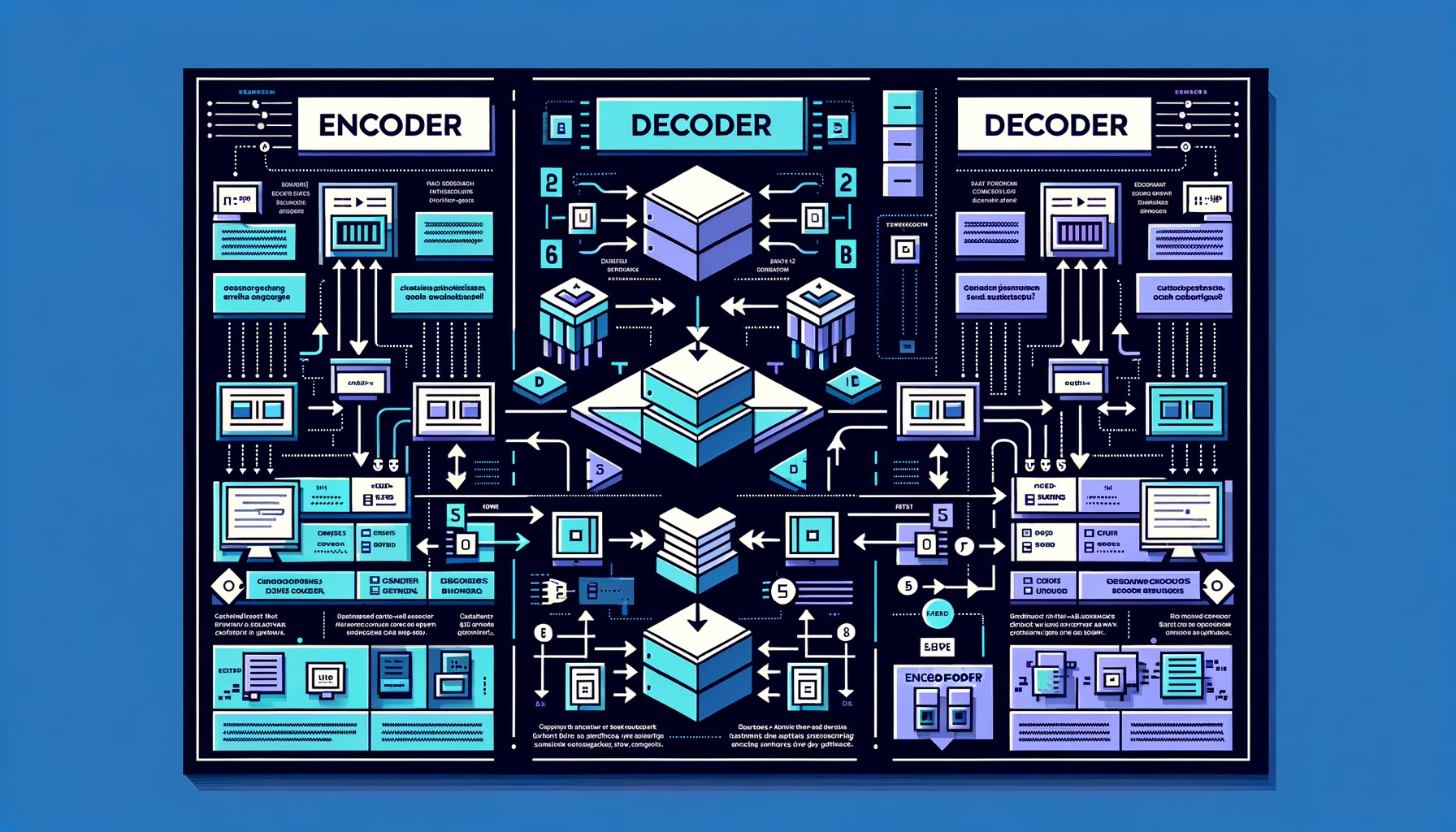
Encoder vs decoder vs encoder-decoder
BERT uses an encoder (understanding), GPT uses a decoder (generation), T5 uses both — different configurations optimized for different GenAI tasks.
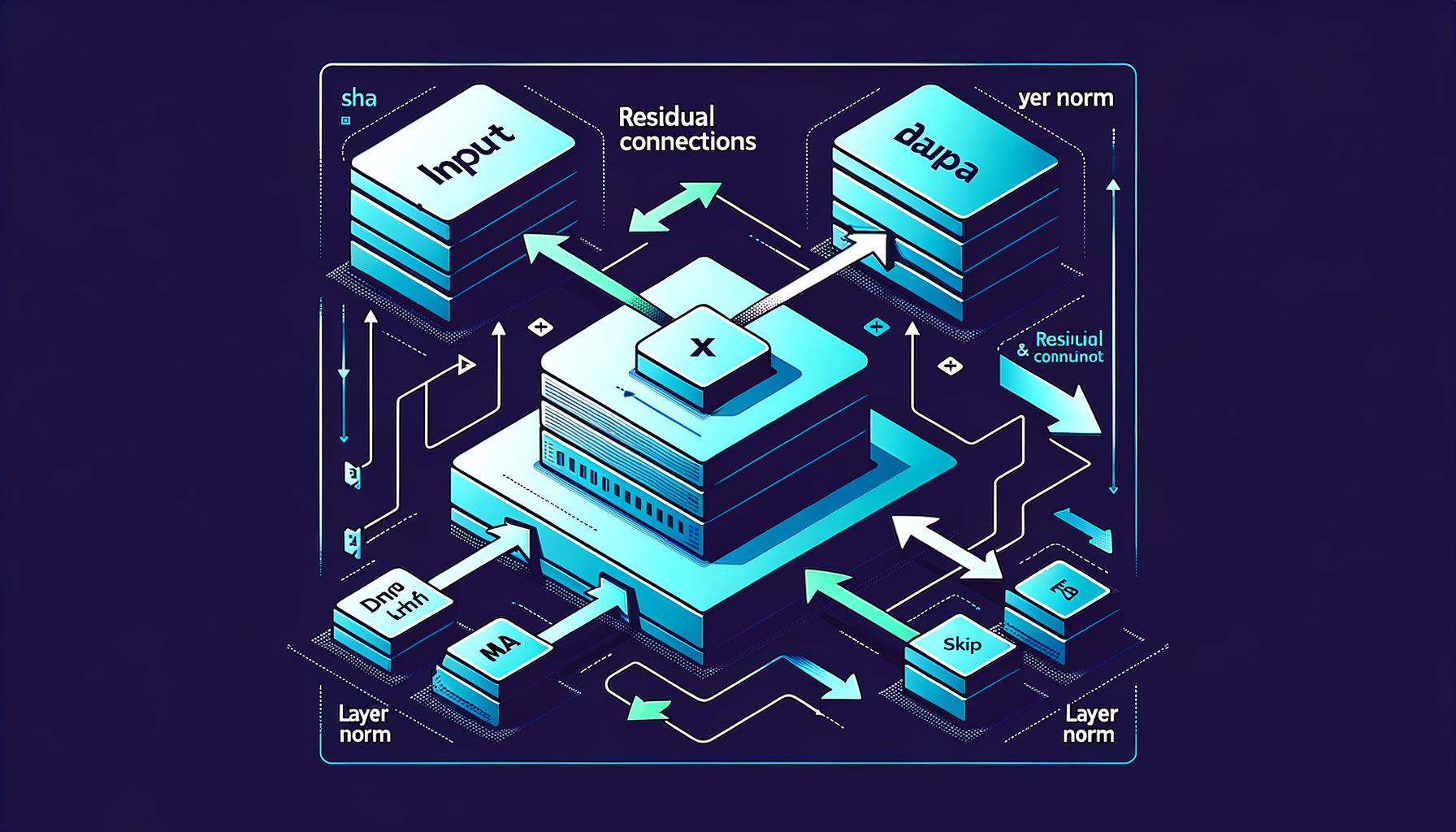
Residual connections & layer norm — stability for deep models
Skip connections add each sub-layer's input to its output, and normalization prevents values from exploding, enabling stable 100+ layer training.

Feed-forward networks — per-token transformation after attention
After attention mixes information across tokens, independent feed-forward layers transform each token's representation with nonlinear activation functions.
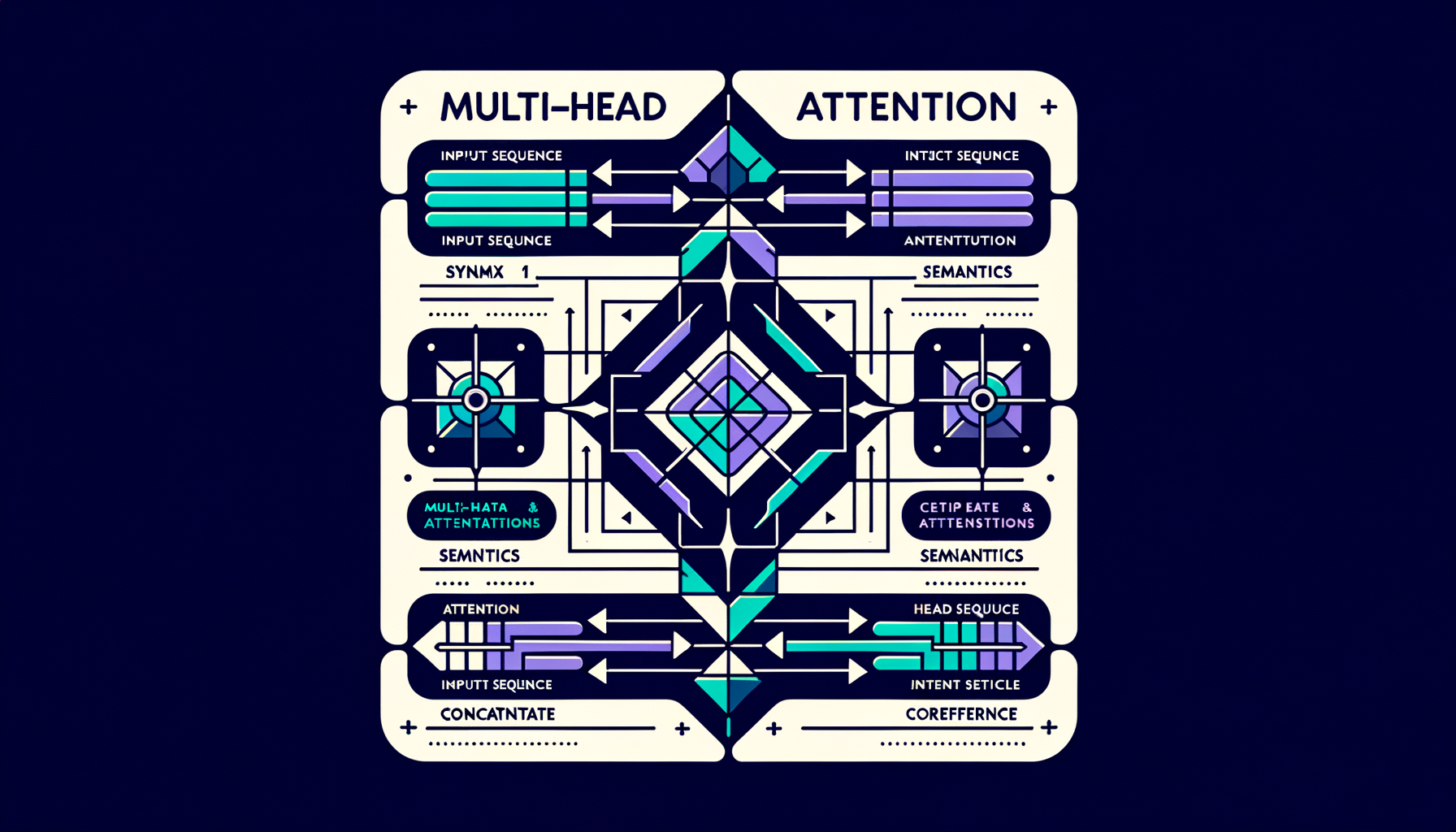
Multi-head attention — parallel perspectives on the same input
Multiple attention mechanisms run simultaneously, each learning to capture different relationship types like syntax, semantics, and coreference.

Query, Key, Value — the three vectors of attention
Tokens generate Q, K, V projections; attention scores come from Q·K dot-product similarity, and the output is V weighted by those scores.

Self-attention — every token looks at every other
Each token computes relevance scores against all other tokens, capturing long-range dependencies in a single parallel computation step.

The Transformer — the engine of modern GenAI
Published in 2017's "Attention Is All You Need," this architecture replaced recurrent networks and became the foundation of every frontier GenAI model.

Token economics — why every token has a price
API providers charge per input and output token; understanding tokenization directly impacts cost estimation, prompt design, and budget optimization.

Positional encoding — teaching word order to parallel models
Since transformers process all tokens simultaneously, position must be explicitly injected via sinusoidal functions or learned embeddings.

Word embeddings — turning tokens into vectors
Each token maps to a learned high-dimensional vector where semantic proximity in space encodes similarity in meaning.
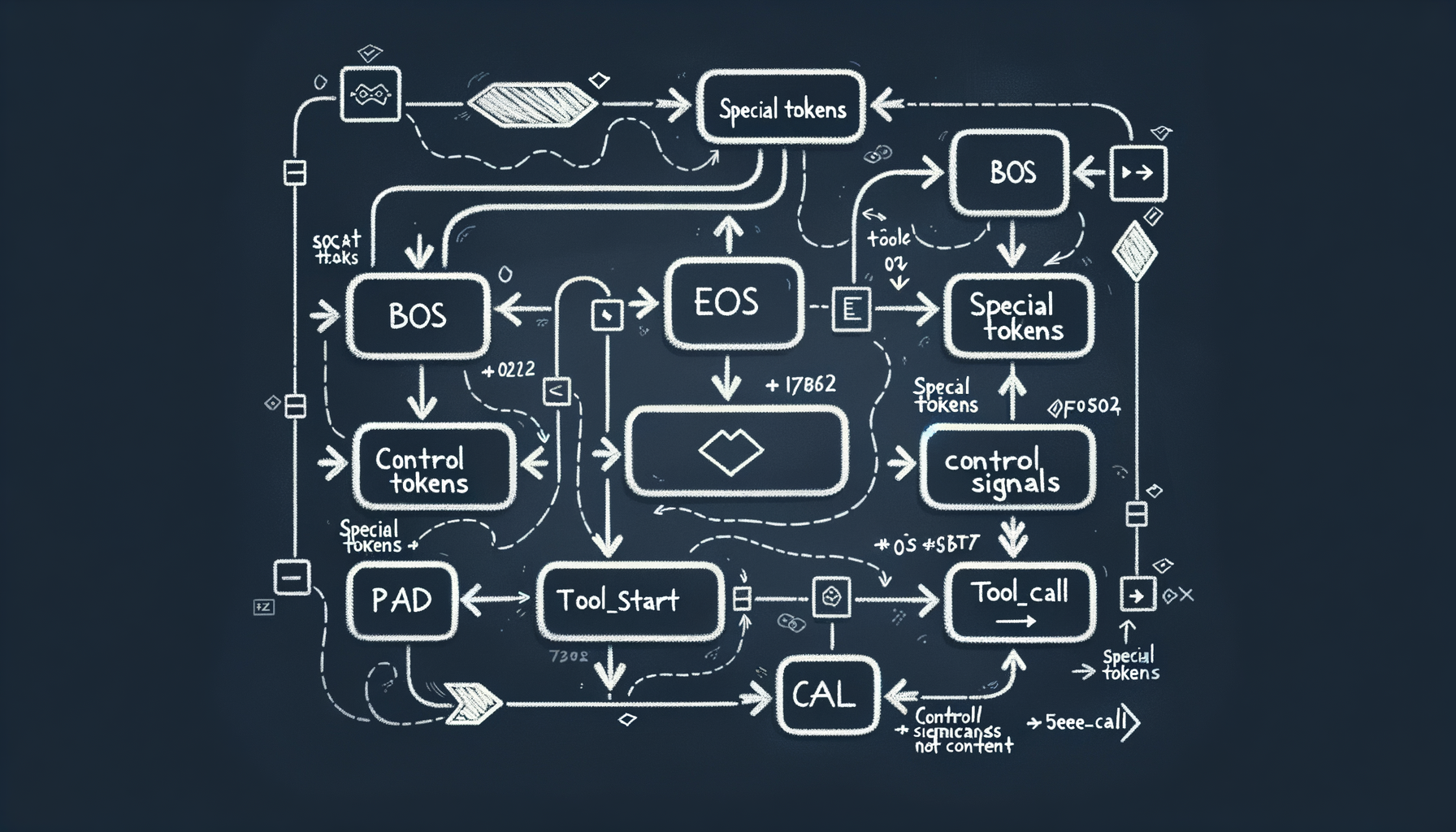
Special tokens — control signals for models
\[BOS\], \[EOS\], \[PAD\], \<\|im\_start\|\>, \<tool\_call\> — reserved tokens that mark boundaries, roles, and structure for the model.

Vocabulary size tradeoffs — why 32K, 50K, or 100K tokens
Larger vocabularies produce fewer tokens per text (cheaper inference) but require bigger embedding tables and more parameters to train.
SentencePiece & tiktoken — tokenizer implementations
SentencePiece (Google) and tiktoken (OpenAI) are the standard libraries for fast, language-agnostic tokenization used across model families.
Byte-Pair Encoding (BPE) — how tokenizers learn to split text
Starting from individual bytes or characters, BPE iteratively merges the most frequent adjacent pairs until reaching a target vocabulary size.

What are tokens — the atoms of language models
Models don't see words or characters; they see tokens — subword units that balance vocabulary size with text coverage.

GenAI timeline — from GPT-1 to today's frontier
A chronological tour: GPT-1 (2018), GPT-3 (2020), DALL-E (2021), ChatGPT (2022), GPT-4 and Claude (2023), multimodal omni models (2024-25).
The GenAI stack — hardware, models, orchestration, apps
From GPU clusters at the bottom to model weights to orchestration frameworks to end-user apps at the top — the full technology stack powering GenAI.
Closed vs open models — APIs vs downloadable weights
OpenAI and Anthropic offer API access; Meta and Mistral release weights — each path has different tradeoffs in cost, control, privacy, and customization.
Parameters — the learned numbers inside a model
Each parameter is a single number learned during training; modern GenAI models have billions, collectively encoding everything the model knows.
The training-inference split — building the brain vs using it
Training costs millions of dollars and takes weeks on thousands of GPUs; inference serves billions of requests cheaply — two fundamentally different engineering problems.

How GenAI generates — one token or step at a time
Text models predict the next token autoregressively; image models denoise step by step — both are iterative generation processes.
Foundation models — one model, many tasks
Massive models pre-trained on broad data that can be adapted to countless downstream tasks without retraining from scratch.
The GenAI modality map — text, image, audio, video, code, 3D
A survey of every output type GenAI can produce today and the distinct model families that power each modality.

How GenAI differs from traditional AI — generation vs classification
Traditional ML sorts, ranks, and predicts from fixed categories; GenAI synthesizes novel outputs by sampling from a learned distribution of possibilities.

What is generative AI — models that create new content
Unlike traditional AI that classifies or predicts, GenAI produces entirely new text, images, code, and audio from learned patterns.